Matrix Factorization에 대해 이해, Alternating Least Square (ALS) 이해
in Data on Recommendation System
Recommendation System_Day8
- DAY8 _ Matrix Factorization에 대해 이해, 이를 푸는 방법론 중 하나인 Alternating Least Square (ALS) 알고리즘 이해
- 각 본문의 출처는 제목 링크와 같습니다.
How do you build a “People who bought this also bought that”-style recommendation engine
Collaborative filtering
The Co-Clustering problem은 두 entities들 간에 상호작용으로 생성되었다고 말할 수 있는 두 가지 유형으로 나뉜다. 예를 들어, user rating은 사용자 특성 (일부 주제 / 범주에 대한 선호도)과 문서적 특성(주제/범주 중 하나 이상에 대한 연결성) 모두에 영향을 받는다. 종종 이러한 유형의 signal은 행렬로 표현되고, 각 차원은 entity types중 하나를 나타낸다. Co-clustering (또는 Biclustering)은 행렬의 행과 열을 동시에 클러스터링 하는 것과 관련된 데이터 마이닝의 용어다. Classical clustering이 object에 속해있는 어떤 것이 같은 type의 다른 object와의 유사성에만 의존한다고 가정한다면, Co-clustering은 pairwise interactions의 유사성에 기반해 two type의 entities를 동시에 grouping하는 방법으로 볼 수 있다.
현실 세계의 데이터는 종종 두 종류의 entities 간의 공동 상호작용에 의해 생성되었다고 말할 수 있는 두 가지 유형으로 나뉜다. 예를 들어, user rating은 사용자 특성 (일부 주제 / 범주에 대한 선호도)과 문서 특성(이들 주제/범주 중 하나 이상에 대한 연결성) 모두에 영향을 받는다. 종종 이러한 유형의 신호는 행렬로 표현되며, 그 중 각 차원은 entity types중 하나를 나타낸다. Co-clustering (또는 Biclustering)은 행렬의 행과 열을 동시에 클러스터링 하는 것과 관련된 데이터 마이닝의 용어다. Classical clustering이 object의 구성원이 (in a group of objects) 같은 type의 다른 object (same entity type) 와의 유사성에만 의존한다고 가정한다면, Co-clustering은 pairwise interactions의 유사성에 기반해 two type의 entities를 동시에 grouping하는 방법으로 볼 수 있다.
User rating document의 이전 예시에서의 signal은 user를 row로, document를 column으로 하는 행렬로, 매트릭스의 원소들은 rating으로 혹은, 또는 document를 향한 user의 선호도 signal로 나타낼 수 있다. 이 행렬을 Co-clustering하는 것은 비슷한 유저들과 비슷한 documents 모두를 카테고리 또는 관심사를 기준으로 동시에 grouping하는 것으로 설명할 수 있다.
Co-clustering은 pairwise interactions가 희박할 때 매우 유용하다. 유저들이 인터넷 뉴스 기사를 읽는 경우를 생각해보자. 같은 뉴스 카테고리에 비슷한 선호도를 가진 두 명의 유저가 있다고 하자. 비록 두 사람이 완벽하게 선호도가 일치한다고 해도, 매일 인터넷에서 제공되는 엄청나게 많고 다양한 뉴스 기사에서 두 사람이 정확히 같은 기사를 읽을 가능성은 극히 낮다. 더욱이, 두 유저가 같은 기사를 읽을 확률은 매우 적다고 가정하는 것이 공평하다. 이 경우 읽은 기사를 기반으로 비슷한 유저를 클러스터링 (혹은 반대로, 중복 독자를 기반으로 기사를 클러스터링) 하는 것은 상당히 무용지물 인 것 처럼 보인다. 그리고 그것은 일반적인 단일 clustering과 비교했을 때, co-clustering 방법이 정말로 빛을 발하는 경우다.
Matrix Factorization
- Model Formulation
co-clustering 문제를 해결하기 위한 가장 인기 있는 알고리즘 중 하나는 (특히 collaborative recommender system) 매트릭스 인자화(Matrix Factorization(MF) 이라고 한다. 가장 단순한 형태로, m users, n items에 의해 rating된 행렬 R ∈ Rm*n 를 가정해보자. R에 MF 테크닉을 적용해 보면 U∈Rm*k, P∈Rn*k (따라서 R ≈ U*P) 두 개의 매트릭스로 구분할 수 있다.

유의해야할 점은 이 알고리즘은 U와 P의 dimension을 새로운 k로 나타낸다는 점이다. 이것은 factorization의 rank 이다. 형식적으로 각 Ri,j 는 ui , pj 의 내적으로 factorized 된다. (ui , pj ∈ Rk). 직관적으로 이 모델은 R의 모든 rating이 효과 k의 영향을 받는다고 가정한다. 더욱이, 이 모델은 이러한 k의 관점에서 볼 때 U와 P의 user와 item 모두를 나타낸다.
따라서 R이 user들이 영화를 보고 rating한 행렬이라고 가정하면, 각 영화가 몇가지 특성으로 한 개나 한개 이상의 카테고리에 묶여 있고, 각 유저는 본인의 선호도에 따라 어떤 영화 카테고리를 좋아하거나 싫어하게 되고, 유저가 영화에 준 rating 은 결국 유저의 characteristics와 영화의 characteristics의 similarity에 의존하게 된다. 여기서 문제는 어떻게 이 카테고리들을 효율적으로 만들 수 있냐는 것이다. 카테고리들은 배우, 감독, 언어, 촬영장소 등등에 대한 선호도, 등 만들수 있는 가능한 features의 수는 어마어마하다.
사실, 우리는 두 entity들 (a user and a movie) 사이에서 pairwise interection하는, 결국 꽤 sparse 한 matrix (ex) 많은 종류의 영화들 때문에 유저들은 영화들의 일부만 rating할 수 있음) 를 통합할 수 있는 co-clustering problem으로 돌아왔다. 직관적으로, 우리는 카테고리/배우/언어 또는 다른 요소에 대한 선호도 (또는 connection)에 의해 유저 (또는 영화)를 대표할 수 있으며, 결국 이것을 바탕으로 클러스터링하려고 노력한다. 문제는, 그러한 요소들이 rating에 미치는 영향을 수치화하기가 꽤 어렵다는 것이다.
그러므로 선형대수로 돌아가서, MF는 아래과 같은 cost function을 최소화하도록 두 행렬 U와 P의 원래 행렬 R의 근사치를 목표로 하는 최적화 과정의 한 형태다.

이 cost function의 앞 부분은 원래의 rating matrix R과 그 근사치인 U x PT 사이의 평균 제곱오차(MSE) 거리 측정이다. 뒷 부분은 "Regularization term"이라 불리며 일반화된 solution을 나타내기 위해 추가된다. (일부 noise를 rating에 줆으로서 overfitting을 막음.)
이 최적화 문제는 Machine learning에 의해 자연스럽게 해결된다. 그 전에, 이 cost function은 두 parameters k와 k와 λ를 적용한다는 점을 알아두자. k와 λ에 대한cost function의 최솟값을 만드는 것 말고도, 이 parameter k, λ의 최적값이 무엇인지 결정해야 한다. 이제부터 k와 λ를 고려하여 이 cost function을 최소로 하기 위해 사용되는 두 가지 최적화 과정을 이야기 할 것이다. 파라메타의 좋은 결정을 위해 일부 상위 수준의 최적화 프로세스(예: Cross Validation (교차 검증)) 가 합쳐질 수 있음을 명심하자.
- 1) Gradient Descent
Gradient Descent는 기계학습 분야에서 널리 사용되는 1차 최적화 알고리즘이다. 개념적으로 최적화 변수에 대한 cost function와 임의의 초기값이 존재한다고 가정하는 단순한 반복 최적화 프로세스다.

반복할 때마다 최적화 변수에 관하여 cost function의 gradient를 다시 계산하고, minimum point로 갈 때까지 cost function의 gradient에 반대방향으로 단계적으로 update한다. 그러나 gradient descent로 cost function을 optimizing하는 것은 local minima로의 수렴을 보장할 뿐이다.
Gradient descent는 MF 모델을 최적화하는데 효과가 있는 것으로 나타났다. 그러나, 최적화할 수 있는 (n⋅k +m⋅k) 파라메타가 있기 때문에, 원래의 rating 행렬의 차원이 높다면 이것은 MF의 optimizer로써 좋은 선택이 아니다. 실제상황에서, 이 경우는 매우 자주 발생할 수 있어서, parallelization mechanism과 MF의 고유한 cost function의 특성을 더 잘 이용해야 한다.
- 2) Alternating Least Squares
MF의 cost function을 다시 보면, 우리는 두 가지 유형의 변수(U와 P)를 배우는 것을 목표로 하고 있으며, 이 둘은 U x PT 로 묶여있다. 실제 cost function은 
그러나 또 다른 흥미로운 사실은 이 부분에 있다. 만약 P를 고정시키고 U에 대해서만 최적화를 시킨다면, 이 문제는 선형 회귀의 문제로 전락할 뿐이다. 선형회귀에서 우리는 주어진 X와 y에 대해 제곱오차 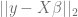

최소제곱법으로 바꾸면 이렇게 된다. 이것은 2단계 iterative optimization process로 되어 있는데, 모든 반복에서 먼저 P를 고정시켜놓고 U를 풀고, 그다음 U를 고정하고 P를 푸는 것이다. OLS 는 unique하고 제일 작은 MSE를 보장하므로, cost function 각 단계에서 감소하거나 변하지 않을 수 있지만 결코 증가하지 않는다. 두 단계를 번갈아 수행하면 수렴할 때 까지 cost function이 계속 감소하는 것을 보장할 수 있다. gradient descent optimization과 비슷하게, local minia로만의 수렴이 보장되며, 궁극적으로 U나 P의 초기 값에 의존한다.
실제 cost function에는 regularization term이 포함되어 있기 때문에 식이 약간 더 길다. 2단계 프로세스에 따르면 cost function은 아래와 같이 두 개의 cost function으로 나눌 수 있다.
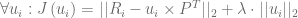

여기에 ui 와 pj 에 해당하는 solution은 아래와 같다.

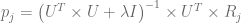
각각의 ui 는 다른 uj≠i 벡터에 의존하지 않기 때문에, 각 단계는 massive parallelization을 사용해 풀 수 있다.
- Missing Values
MF는 rating matrix R에서 missing value을 허용한다. 이 때 cost function은 아래와 같이 바뀐다.
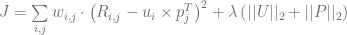
where
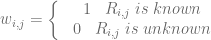
여기에 ui 와 pj 에 해당하는 solution은 아래와 같다.
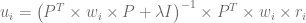
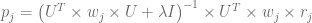
Matrix Completion via Alternating Least Square(ALS)
Matrix Factorization: Objective and ALS Algorithm on a Single Machine
이것에 대한 일반적인 접근법은 Matrix factorization인데, 여기서 우리는 비교적 작은 숫자 k (예: k ≈ 10)를 고정시키고, 각 a의 유저 u를 k 차원 벡터 xu 로 요약하고, 각 a의 아이템 i를 k 차원 벡터 yi 로 요약한다. 이러한 벡터들을 factors(요인)이라고 한다.
그 후, item i에 대한 유저 u의 rating을 예측하기 위해서 우리는 단순히 rui ≈ xTu yi 를 예측한다. 이것을 행렬형태로 만들 수 있는데, x1,…, xn ∈ Rk 가 유저들에 대한 factor들이 되게 하고 y1,…, ym ∈ Rk 가 그 아이템에 대한 factor들이 되게 한다. 그 후, k × n user matrix X와 k × m item matrix Y를 다음과 같이 정의한다.
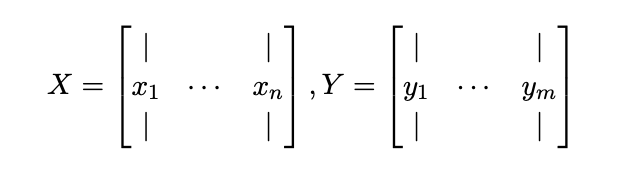
우리의 목표는 완전한 rating matrix인 R ≈ XT Y를 추정하는 것이다. 우리는 이 문제를 objective function을 최소화 하고 최적의 X와 Y를 찾는 것을 목표로 하는 최적화 문제로 만들 수 있다. 특히, 우리는 observed ratings의 Least Squares error (최소 제곱 오차)를 최소화하는 것을 목표로 한다.
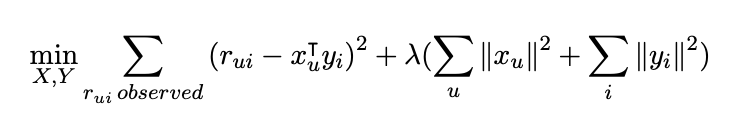
이 objective function이 ( xTu yi term 때문에) non-convex라는 점에 주목하자. 이것은 ‘NP-hard’ optimization 문제와 같다. Gradient descent는 approximate한 방법으로 사용될 수 있지만 속도도 느리고 iteration cost가 많이 든다. Variable X set을 고정시키고 이를 상수로 취급하면 이 때 objective function은 Y의 convex function 이 되고 반대의 경우도 가능하다.(Variable Y 고정 -> X의 convex function)
그러므로 우리는 Y를 고정시키고 X를 optimize한 다음, X를 고정시키고 Y를 optimize할 것이고 이를 수렴할 때 까지 반복한다. 이 방법이 ALS (Alternating Least Squares) 이다.
우리의 objective function에 대하여 ALS 알고리즘은 다음과 같다.

알고리즘 computational cost를 분석해보면, 각 xu 를 업데이트 하는 데 O(nuk2 + k3) 의 비용이 든다. 여기서 nu 는 유저 u가 rating한 item의 수이다. 이와 유사하게 각 yi 를 업데이트 하는 데 O(nik2 + k3) 의 비용이 든다. 여기서 ni 는 item i 에 rating한 user 수이다. 일단 우리가 행렬 X와 Y를 계산하고 나면, 여기엔 예측을 할 수 있는 몇 가지 방법이 있다.
1) 앞에서 이야기 한 방법으로각 유저 u와 아이템 i에 대해 간단히 rui ≈ xTu yi 예측하는 것이다. 하지만 모든 user-item 쌍을 찾기 위해서는 O(nmk)의 비용이 들 것이다. 즉 실제 데이터 셋에 적용할 경우 엄청 비쌀 것이다.
2) xu 와 yi 를 다른 학습 알고리즘의 features로 사용하여 이 feature들과 다른 feature들을 합쳐 다른 예측 알고리즘에 활용하는 것이다.
