Cosine similarity 와 Pearson correlation을 사용한 User based 및 Item based nearest neighbor Collaborative Filtering에 대한 이해
in Data on Recommendation System
Recommendation System_Day6
- DAY6 _ Cosine similarity 와 Pearson correlation을 사용한 User based 및 Item based nearest neighbor Collaborative Filtering에 대한 이해
- 각 본문의 출처는 제목 링크와 같습니다.
Collaborative Filtering
– Collaborative Filtering (CF)
- Recommendation system의 가장 prominent한 접근법
- 대형 상업용 전자상거래 사이트에서 사용
- well- understood, , 다양한 알고리즘 존재
- 많은 도메인에 적용 가능 (책, 영화, DVD 등)
- Basic assumption and idea
- 사용자가 카탈로그 항목에 대한 rating 부여(implicitly or explicitly)
- 과거 취향이 비슷했던 고객들은 미래에도 비슷한 취향을 가질 것
– Pure CF approaches
- Input
- Only a matrix of given user–item ratings
- Output types
- 현재 user가 특정 아이템을 어느 정도 좋아할지 싫어할지를 나타내는 예측 (numerical)
- 추천 품목 리스트 상위 N개
– User‐based nearest‐neighbor
- The basic technique
- “active user” (Alice) 와 Alice가 아직 보지 못한 item i 가 주어진 경우
- 과거에 Alice와 같은 아이템들을 좋아한 사람들 중에 item i를 평가한 user의 set을 찾는다.
- ex) 만약 Alice가 item i 를 좋아한다면, 예상할 수 있는 rating들의 평균값을 사용
- 이 방식을 Alice가 아직 보지 못한 모든 item들에 적용하여 best-rated item을 추천한다.
- do this for all items Alice has not seen and recommend the best-rated
- Basic assuption and idea
- 사용자가 과거와 취향이 비슷하다면 미래에도 비슷한 취향을 가지게 될 것이다.
- User preferences는 시간이 지남에 따라 안정적이고 일관성 있게 유지된다.
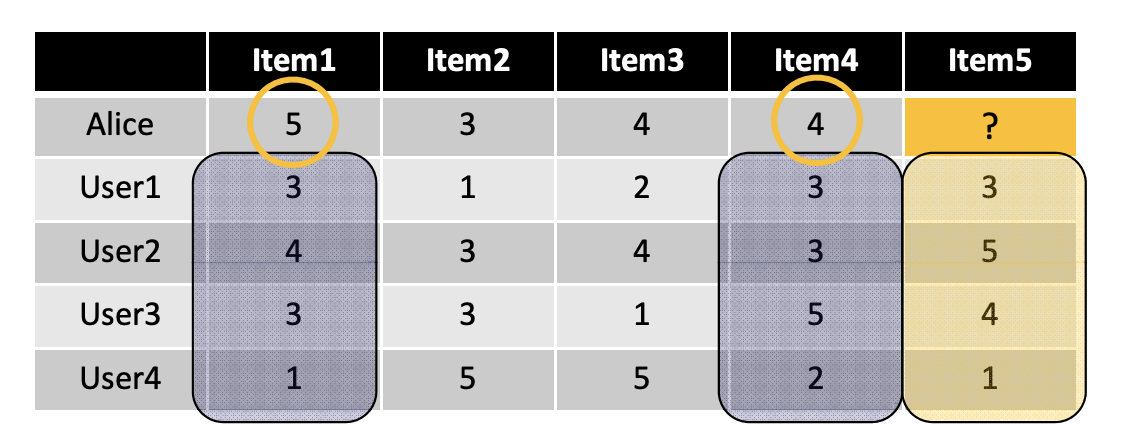
ex) Alice가 item5를 얼마나 좋아할지 결정해라
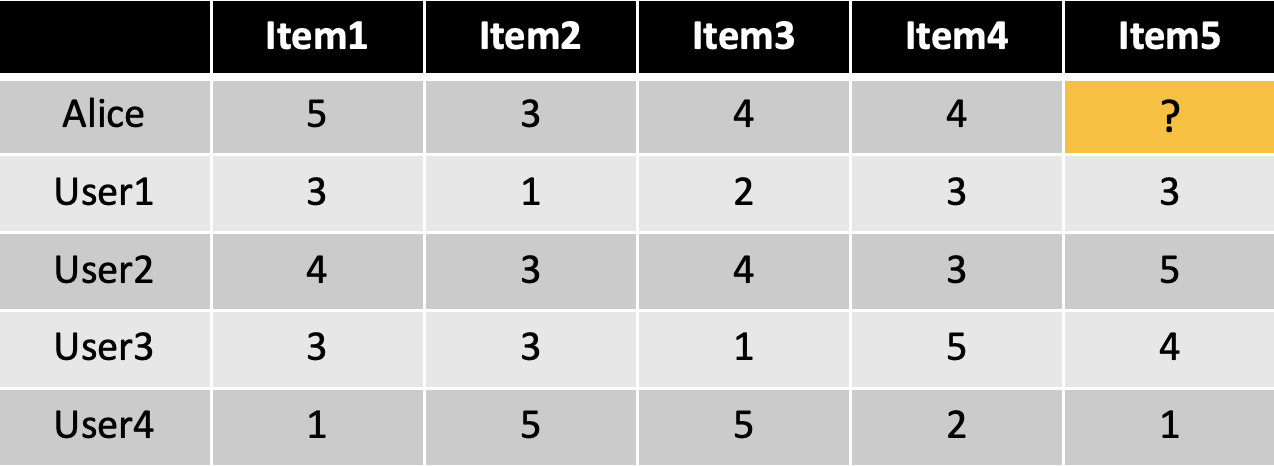
- Some first questions
- How do we measure similarity?
- How many neighbors should we consider?
- How do we generate a prediction from the neighbors’ ratings?
– The Pearson Correlation similarity measure
A popular similarity measure in user-based CF : Pearson correlation (피어슨 상관계수)
between -1 and 1
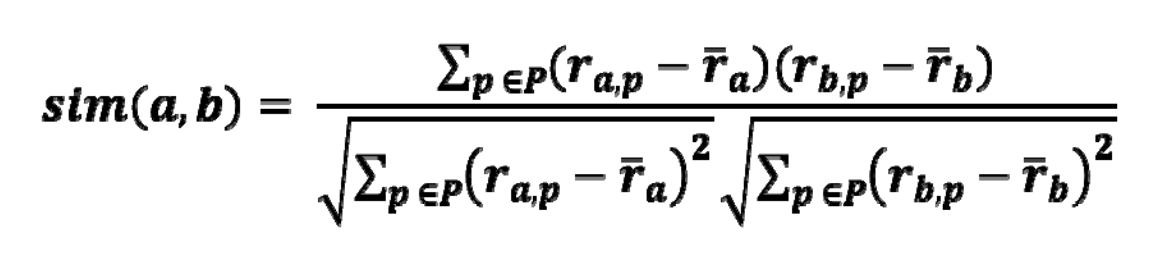
a, b = users
ra,p : user a 의 item p 에 대한 rating
p : a 와 b 모두에게 rating 받은 item set
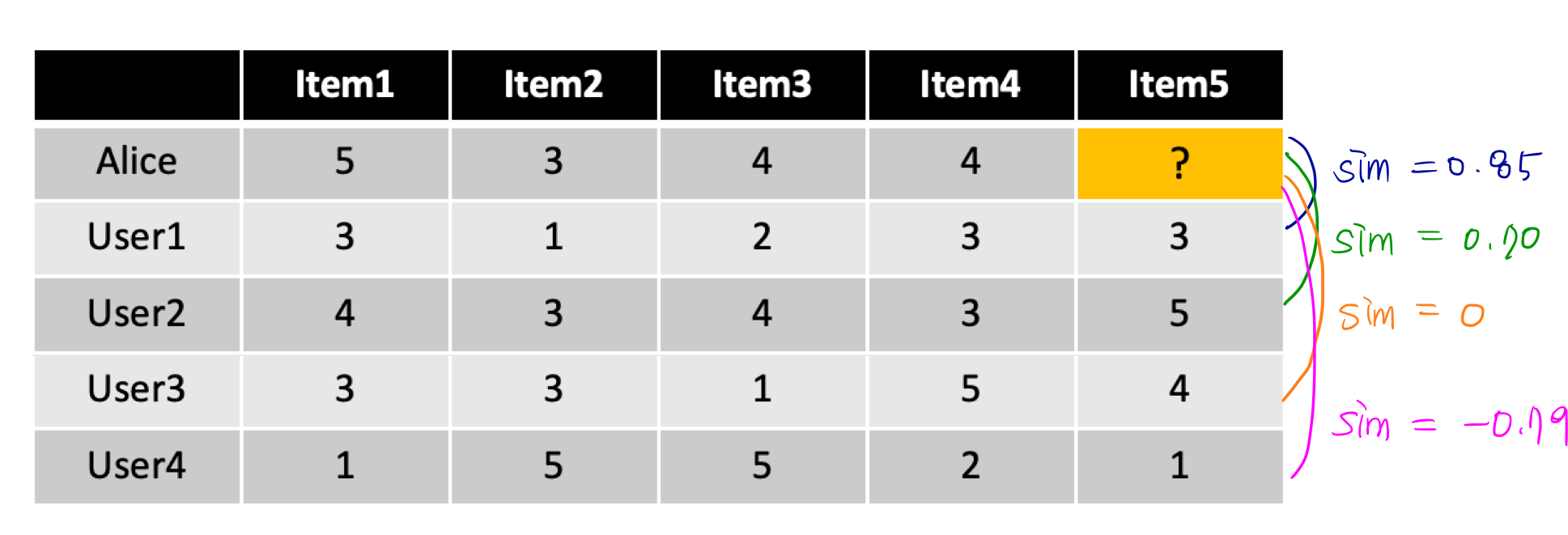

*손계산 참고

Pearson correlation : rating의 차이를 고려한다.
다른 방법에 비해 일반적인 domain에서 잘 작동한다.
ex) 코사인 유사도 (cosine siilarity)
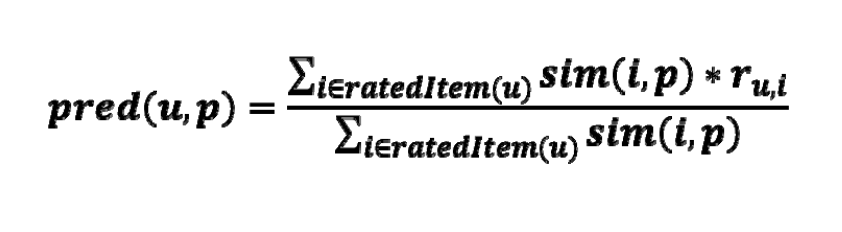
Making prediction
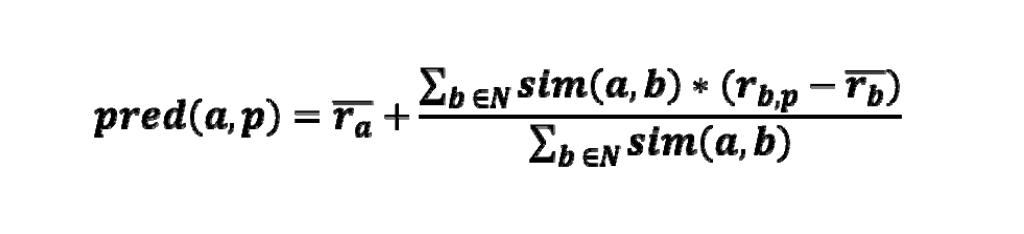
a, b = users
ra,p : user a 의 item p 에 대한 rating
p : a 와 b 모두에게 rating 받은 item set
- 평균에 상관없이 아직 모르는 item i 에 대한 neighbor들의 rating을 계산한다.
- combine the rating differences -> a 를 weight로 similarity 사용
- 다른 active user’s average로부터 neighbors’bias를 더하거나 빼고, 이것을 예측값으로 사용한다.
Improving the metrics / prediction function
모든 neighbor의 rating이 동등하게 “가치 있는” 것은 아닐 것이다.
- 일반적으로 다수에게 선호되는 item에 대한 예측값 보다 유저마다 선호도 차이가 심할 것으로 예상되는 item에 대한 예측값이 더 유의미 하다.
- Possible solution : variance가 높은 item에 weight를 더 준다.
Value of number of co‐rated items
- Use “significance weighting” eg) 같은 rating의 item 수가 낮을 때, weight를 선형적으로 감소시킨다
Case amplification
- Intuition : 유사성 값이 1에 가까운 ‘매우 유사한’ neighbor에게 더 많은 weight를 실어준다.
Neighborhood selection – Use similarity threshold or fixed number of neighbors
– Memory‐based and model‐based approaches
- User‐based CF is said to be “memory‐based” – rating matrix는 neighbors를 찾는데 직접 사용되거나 예측하는데 사용됨 – 대부분의 현실적 시나리오에 맞춰 확장되지 않음 – 대형 전자상거래 사이트에는 수천만 명의 고객과 수백만 개의 아이템이 있다.
Model‐based approaches
오프라인 전처리 또는 “모델 학습” 단계를 base로 한다.
- 런타임에는 학습된 모델만 사용하여 예측한다.
- 모델은 주기적으로 update / re-train 된다.
- 다양한 technique들이 사용된다.
- model-building / updating에 비용이 많이 들 수 있다.
- item-based CF는 model-based 접근법의 한 예이다.
– Item‐based nearest‐neighbor
- Basic idea : items (not users) 의 similarity를 이용하여 예측함
- Example
- item 5 와 비슷한 다른 item 찾기
- 찾은 비슷한 item들에 대한 Alice의 rating을 받아서 item 5의 rating을 예측함.
– The cosine similarity measure
item to item filtering 에서 좋은 결과를 도출함
rating : n차원 공간에서의 벡터로 표현
벡터 사이의 각도를 기준으로 Similarity를 계산한다.
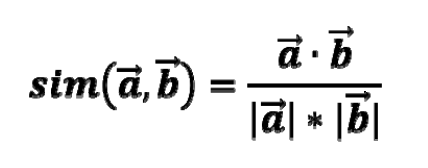
Adjusted cosine similarity
average user ratings 를 고려하여, 원래 ratings를 변환한다.
U: item a 와 b에 등급을 모두 매긴 users set
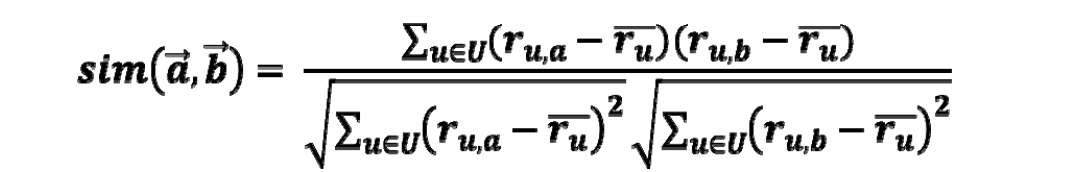
Making prediction
A common prediction function:
Neighborhood size는 일반적으로 특정 크기로 제한된다.
모든 neighbor들이 예측을 위해 고려되지는 않는다.
MovieLens 데이터 세트를 분석한 결과, “대부분 실제 상황에서 20~50명의 neighbor이 합리적인 것 같다” (Herlocker 등, 2002)
– Pre-processing for item-based filtering
item-based filtering은 확장성 문제를 해결하지 못한다
전처리 by Amazon.com (in 2003)
- 모든 set의 item similarity를 미리 계산한다.
- user가 rating한 item만 고려하기 때문에, 실제로 돌아갈 때 사용되는 neighbor은 적다.
- Item similarity는 user similarity보다 더 안정성 있어야 한다.
Memory requirements
이론상 최대 N2 쌍의 유사성(N = item 수)이 저장될 것
실제로 이것은 상당히 낮다 (items with no co-ratings)
Further reductions possible.
co-ratings을 위한 threshold를 최소화한다.
neigborhood size에 제한을 둔다.
– More on ratings
- Explicit ratings
- 아마 가장 정확한 rating 일 것이다.
- 가장 많이 사용. (1~5, 1~7 Likert scales)
- Main problem
- 사용자들은 항상 많은 item에 대한 평가를 충분히 하려 하지 않는다.
- 이에 따라 사용 할 수 있는 rating이 너무 적을 수 있음 → sparse한 rating matrices → 좋지 않은 추천 결과
- 어떻게하면 user에게 더 많은 항목을 평가하도록 할 수 있을까?
- 사용자들은 항상 많은 item에 대한 평가를 충분히 하려 하지 않는다.
- Implicit ratings
- 일반적으로 추천 시스템이 내장된 웹 쇼핑 사이트이나 응용 프로그램에 의해 수집된다.
- 예를 들어 많은 추천 시스템은 고객이 물건을 사는 행동을 긍정적인 rating이라고 해석한다.
- 클릭, 페이지뷰, 페이지에 머문 시간, Demo download
- Implict ratings은 user의 추가 노력 없이 지속적으로 수집할 수 있다.
- Main problem
- user 행동의 올바르게 해석되었는지 여부는 확신할 수 없다.
- 예를 들어, 사용자는 자신이 구입한 모든 책을 좋아하지 않을 수 있고, 다른 누군가를 위해 책을 샀을 수도 있다.
- Implict ratings은 Explict rating 외에 사용할 수 있음; 해석의 정확성에 대한 question
Machine Learning Summer School @CMU 2014 중 Introduction to Recommendation System Lecture 중 일부
- Video _Machine Learning Summer School 2014 in Pittsburgh (45:18 ~ 64:33)
- Slides_Recommender Systems (Machine Learning Summer School 2014 @ CMU) (31p ~ 58p)
User-User Collaborative Filtering
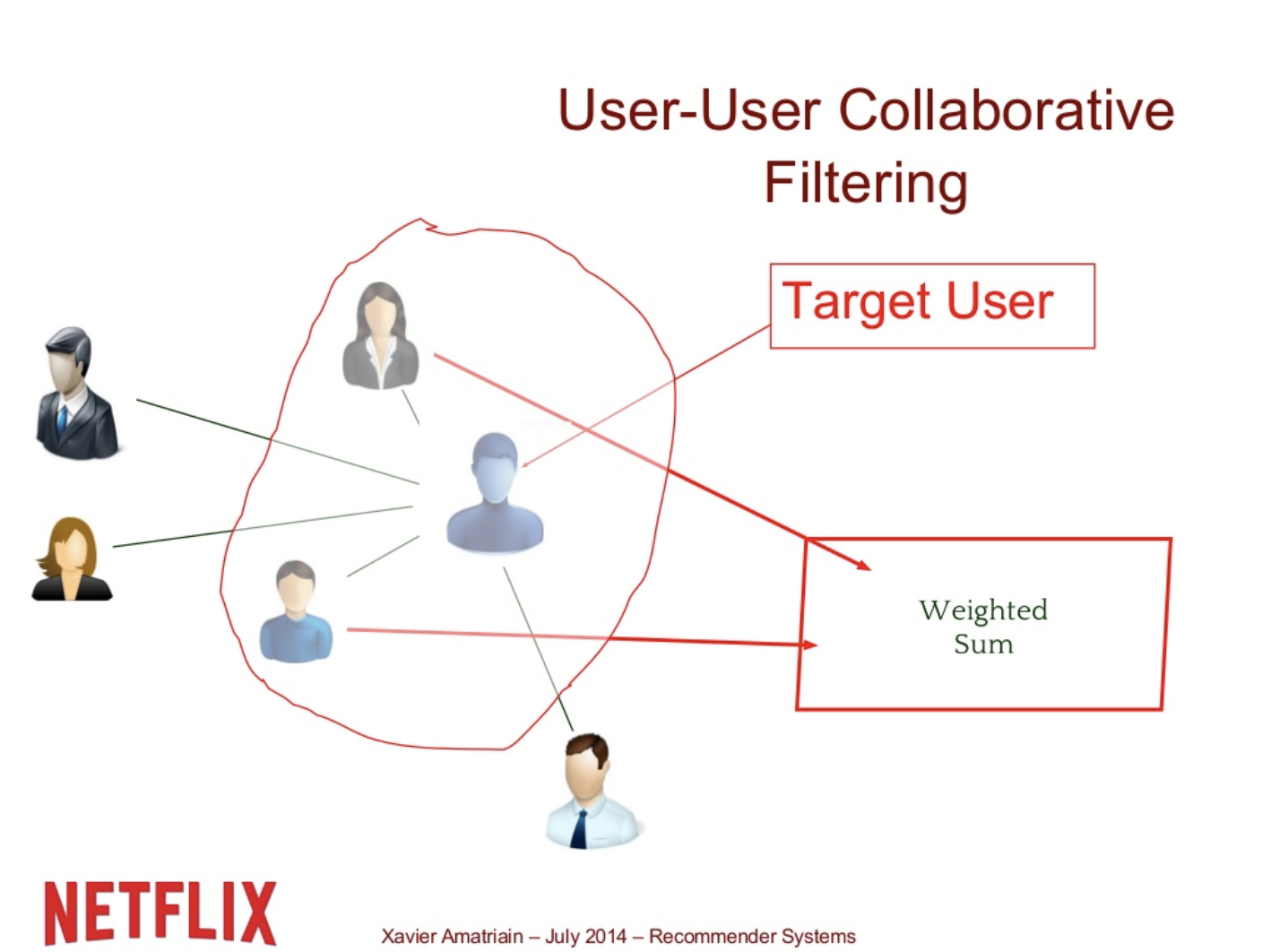
다른 유저들의 rating들을 user와의 거리순으로 배열한 후 가까운 몇 명의 neighbor 을 거리순 가중합을 통해 rating을 예측한다. 이 때 key는 weight를 어떻게 설정하느냐 이다.
1) boundary를 결정하거나 (몇 명을 더하여 rating을 평가할 것인가)
2) weight를 어떻게 설정할 것인가
유저들이 너무 많으면 -> data sparsity (듬성듬성한 데이터)
즉 이방법은, 추천시스템에 대해 설명하기 좋고 나쁜 방법은 아니지만 뚜렷한 제약이 존재한다. 적은 수의 아이템과 유저들이 있을 경우 유용할 수 있지만 일반적인 상황에선 그렇지 않다.
User-based CF Ex.
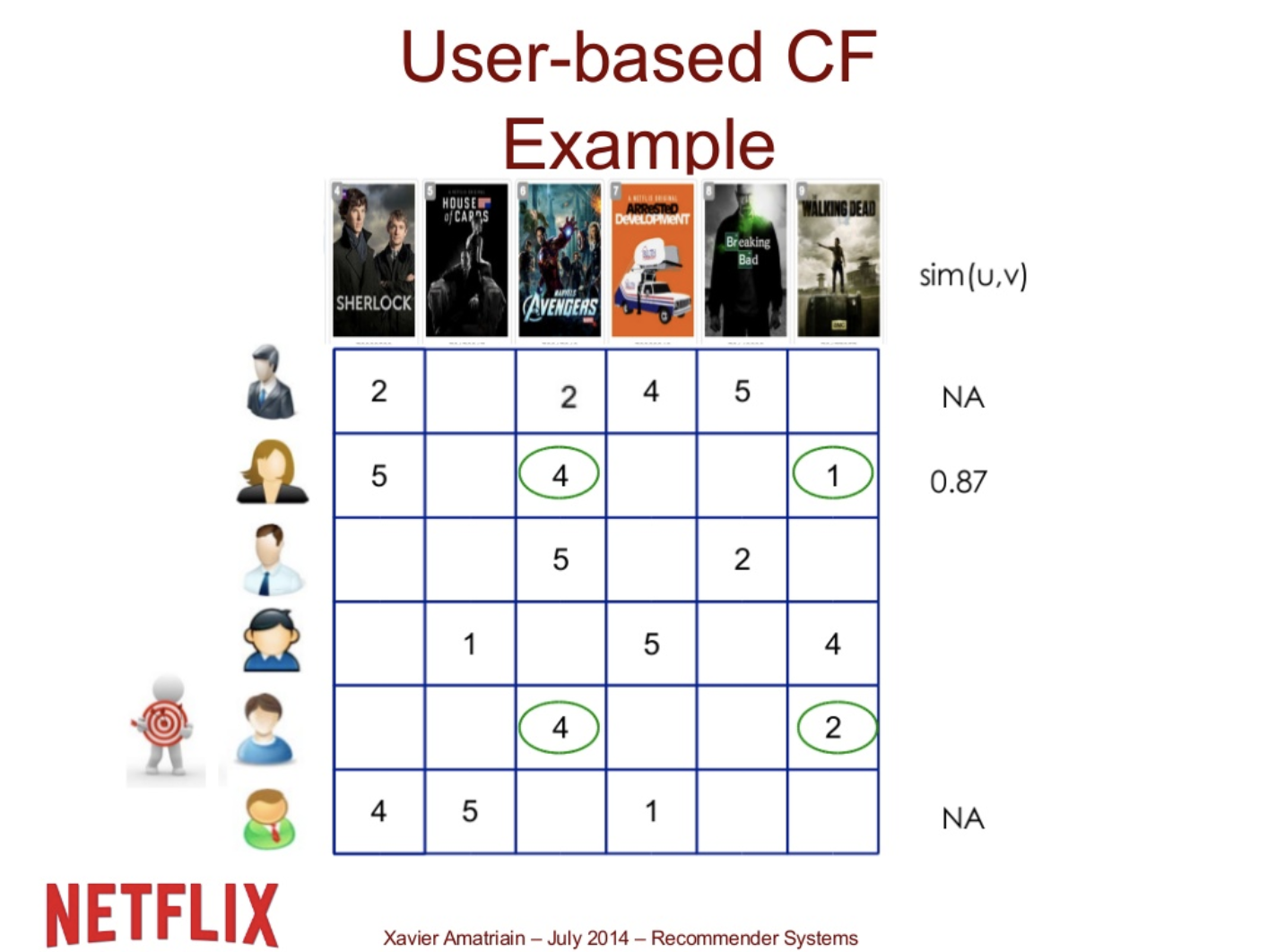
User 5 를 Target user 라고 하자. User 5 와 User 2와의 correlation은 0.87이지만 6번째 사람과의 correlation은 구할 수 없다. (공통된 rating이 없기 때문)
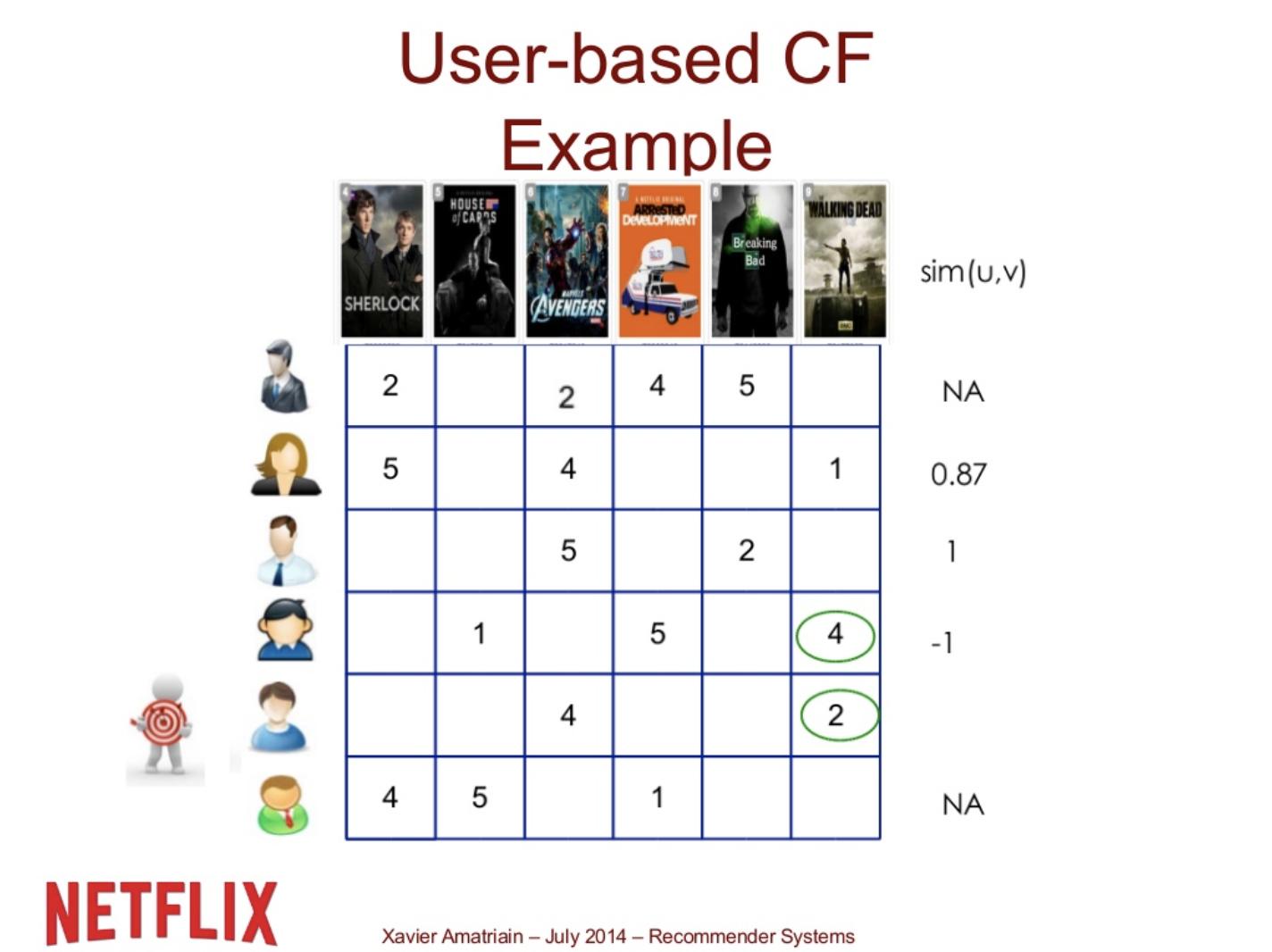
User5와 User 3의 correlation은 1이다. 공통된 item에 대한 rating이 1개 밖에 없고 , rating이 다 각 user의 평균을 넘기 때문에 (5 > 2.5, 4 > 3) correlation은 1이 된다. (둘다 평균을 넘는다면 1, 하나는 평균을 넘고 하나는 평균을 못넘는다면 -1) User 4와는 공통된 item에 대한 rating이 1개이고, 이 rating이 user5는 평균보다 낮고 (2 < 2.5, user4는 평균보다 높으므로 (4 > 3.3) correlation은 -1이 된다.
이 correlation들이 target user와의 similarity가 된다. 이 세명의 유저들의 rating을 combine하여 계산하여 target user의 rating을 예측한다.
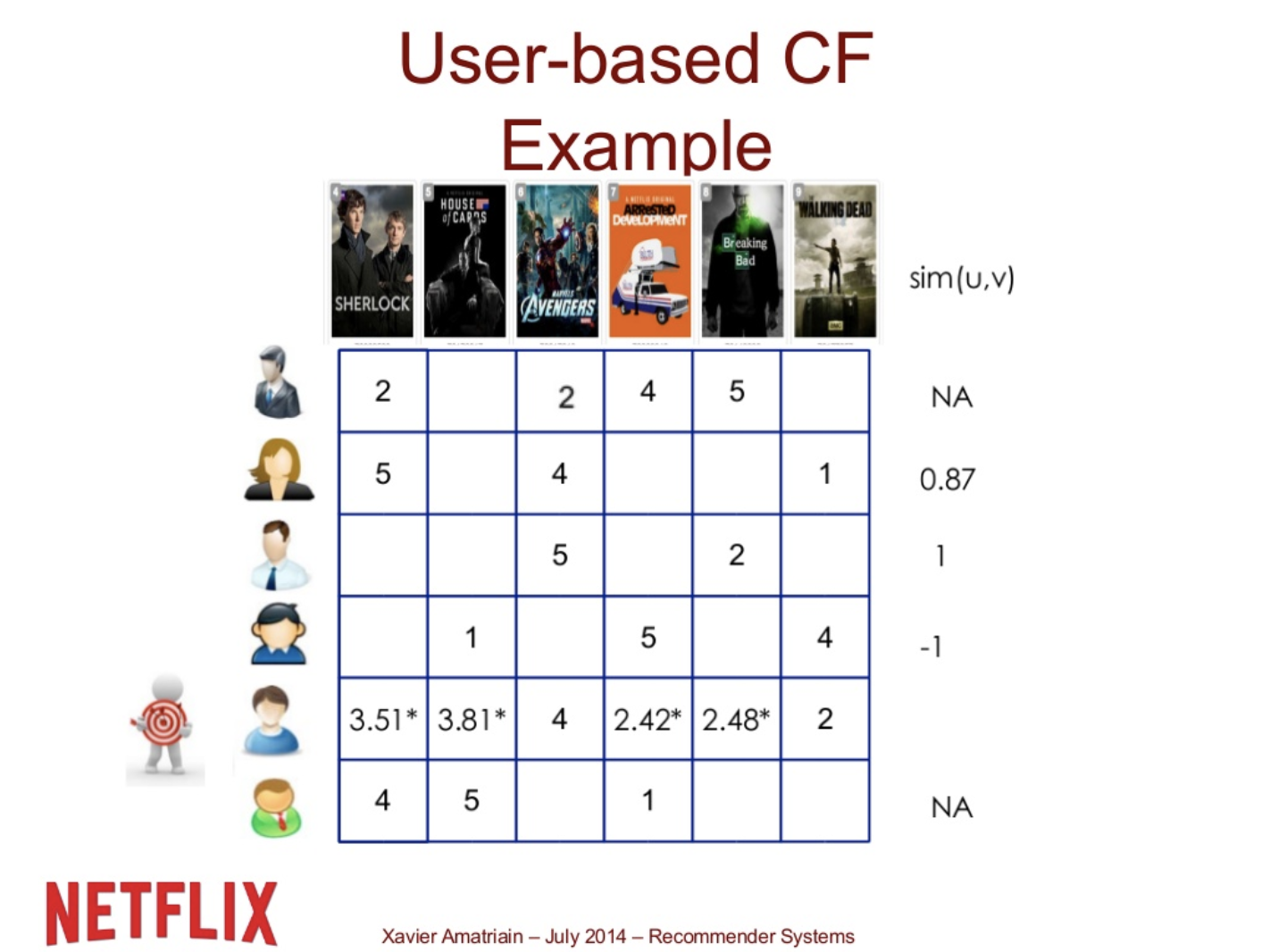
(좋은 예측은 아니다 하지만 단순한 평균을 이용하는 거 보다는 낫다)

Item-Item Collaborative Filtering

user based와 아이디어는 비슷하나 유저를 기준으로 아이템을 비교하던 것을 아이템을 기준으로 유저를 비교한다.
1) cosine similarity

2) correlation

3) Adjusted cosine similarity


Item-based CF Ex.

The Sparsity Problem
- 우리는 주로 큰 데이터셋을 다루게 된다.

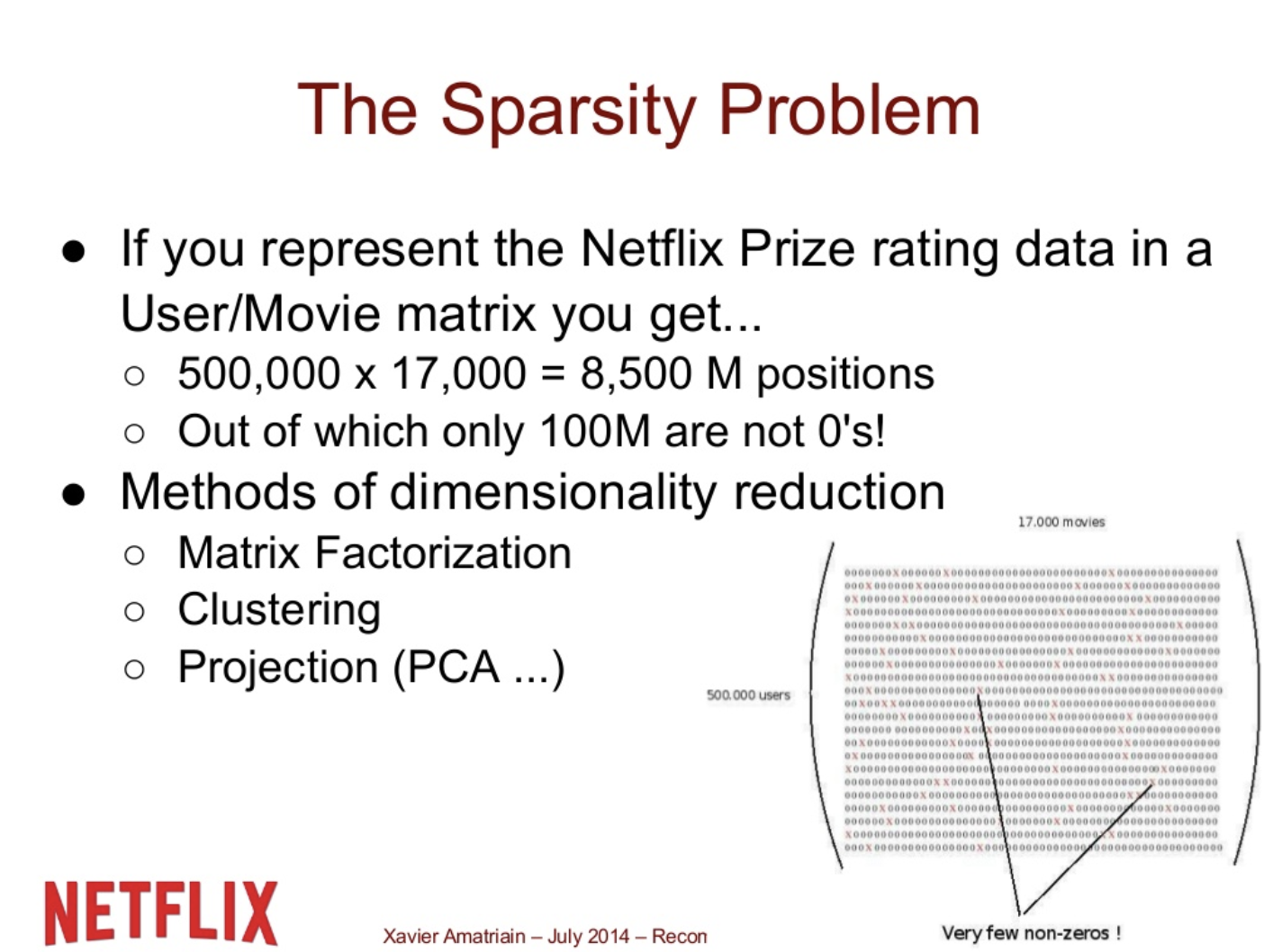
원래 데이터에는 수많은 0이 생기기 때문에 dimension reduction을 해야 powerful한 결과를 낼 수 있다.

Similarity Functions for User-User Collaborative Filtering
- 간단한 번역
일반적으로 user-user 협업 필터링은 사용자를 비교하기 위해 Pearson correlation을 사용해 왔다. 초기 연구는 Spearman correlation과 Cosine similarity로 시도했지만, Pearson이 더 잘 작동한다는 것을 발견했고, 이 문제는 꽤 오랫동안 다시 논의되지 않았다.
내가 LensKit 논문에 대한 이러한 알고리즘적인 결정을 리뷰할 때, 나는 mean-centered vectors ( ‘Adjusted Cosine’이라고도 함)에서 Cosine similarity를 시도했는데, 심지어 어떤 가중치가 없는 Pearson correlation보다 (오프라인 평가 지표에서) 더 잘 작동한다는 것을 알았다. 그래서 Cosine similarity를 사용하길 추천한다. 왜 효과가 있을까?
Pearson correlation를 사용하는 유저들 사이에서 similarity를 계산하는데에 두 가지 문제가 있다.
1) 한 사용자가 rating을 했지만 다른 사용자가 rating을 하지 않은 item으로 무엇을 할 것인가 하는 문제다. 이를 처리하는 간단하고 통계적으로 정확한 방법은 두 사용자 모두 rating을 한 itmes만 고려하고 이를 일관되게 수행하는 것이다. 이에 따라 다음과 같은 공식이 나오는데, 여기서 Iu는 user u 에 의해 rating 된 item이다.
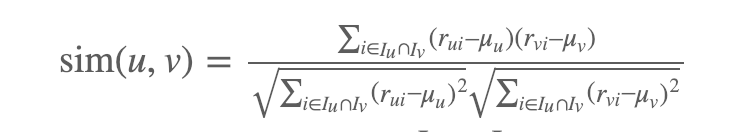
μu는 Iu ∩ Iv (공통으로 rating된 item)의 rating만 놓고 계산해야 하지만, 그것이 현실에서 상당한 차이를 만들것 같지는 않다.
2) rating이 거의 같은 item이 없는 user들이 매우 높은 similarity를 가질 것이라는 점이다. 하나의 rating에 대한 Pearson correlation는 정의되지 않는다. 그러나 각 유저들이 많은 item에 대해 rating을 했을 때, 이들이 두개의 동일한 item에 대해 rating을 했다는 것은 그들이 완전히 비슷하다고 말할 수 있는 좋은 근거가 아니다. 이 문제를 다루기 위한 전형적인 방법은 similarity에 min(|Iu+Iv|,50) / 50 를 곱하여 가중치를 주는 것이다. (Herlocker et al., 1999) 이를 통해 user들이 최소한 50여개의 rating에 공통점을 가질때까지 similarity를 선형적으로 감소시킨다. 이것은 다소 임시적인 방법이지만, Pearson correlation을 이용하여 추천 시스템의 성능을 향상시킨다.
그래서 코사인은? 첫째, mean-centered vectors에 대한 Cosine similarity는 Pearson correlation과 매우 유사하다. (rui \^는 rating rui–μu 을 정규화 한 것)
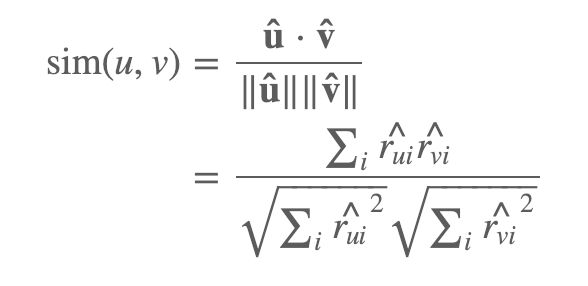
만약 우리가 Iu ∩ Iv (공통으로 rating된 item)를 합한다면, 정확히 Pearson correlation과 일치한다. 그러나 만약 user u가 item i에 대한 rating이 없을 때마다 rui\^=0으로 Iu ∪ Iv 를 합한다면 상황은 달라진다. 유저가 정확히 같은 item에 rating 한 경우, 그것은 pearson correlation을 유지한다. 그러나 한명의 user만 rating을 하고 다른 user는 rating하지 않았다면, 해당 rating은 분자와는 멀어지지만 분모에는 여전히 영향을 미친다. (0을 곱하기 때문) 그래서 이 similarity function는 공동으로 rating한 item / user item set sizes = (|Iu ∩ Iv| / √|Iu|√Iv|)에 기반하여 스스로 감소한다. (rating 이 연산에 영향을 미치기 때문에 엄격한 linear scaling은 아니지만, 이 프레임은 기본 아이디어를 전달하는 데 유용하다고 생각) 오프라인 실험에서는 이런 다이나믹한 self-damping이 유의한 가중치보다 더 효과적이고, 50이라는 상당히 임의적인 cutoff에 의존하지 않는다는 추가적인 장점도 있다.
user-user CF(Breese et al., [1998])를 위해 cosine similarity를 사용한 최초의 연구는 similarity를 계산하기 전에 mean-center data 가 아니었다. similarity 계산을 위한 mean centering은 중심은 item-item 협업 필터링 전까지 괜찮은 visibility가 없었고, 자주 user-user backport되지 않았다.
협업 필터링에 관한 위키피디아 글, 일부 참고문헌은 Cosine similarity와 Pearson correlation (공통 item만 고려)을 똑같은 계산으로 정의한다. 하지만 Pearson correlation은 모든 item들을 고려하는 self-damping 장점을 가지고 있지 않다.
모든 user에 대한 Mean-centering과 합계는 일반적으로 similarity를 보기 위해 user들을 비교하는 내가 아는 최선의 방법이다. 어떤 특정 애플리케이션에 가장 적합한지 보기 위해 데이터(및 이상적인 유저)로 실험하는 것도 괜찮지만, 좋은 시작점은 mean-centered cosine이다.
