2019 구글 머신러닝 스터디잼
in Data on Machine Learning
2019 구글 머신러닝 스터디잼_입문
- Google Cloud Speech API: Qwik Start
- Cloud Natural Language API: Qwik Start
- Speech to Text Transcription with the Cloud Speech API
- Entity and Sentiment Analysis with the Natural Language API
Speech와 Natural Language 각각의 API를 요청하고 호출하는 방법과 이를 이용하는 방법과 관련된 가벼운 실습으로 진행된다.
Google Cloud Speech API: Qwik Start
- audio -> text를 만드는 API 생성, 호출
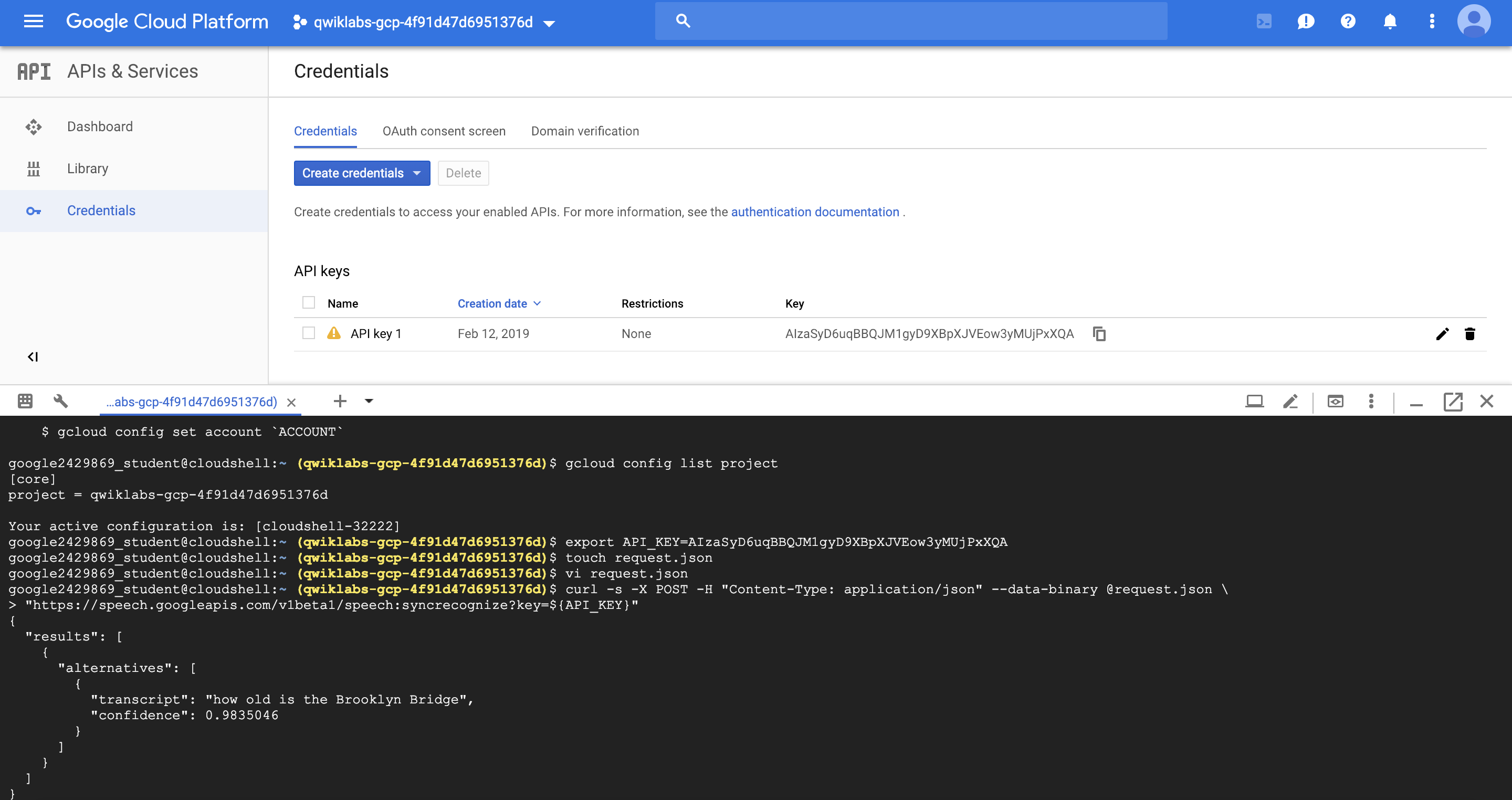
짧은 오디오 예제지만 정확도가 무려 98%에 이르는 것을 볼 수 있다.
$ vi request.json
에 해당하는 내용은 아래와 같다.
{
"config": {
"encoding":"FLAC",
"sample_rate": 16000,
"language_code": "en-US"
},
"audio": {
"uri":"gs://cloud-samples-tests/speech/brooklyn.flac"
}
}
{
"results": [
{
"alternatives": [
{
"transcript": "how old is the Brooklyn Bridge",
"confidence": 0.98267895
}
]
}
]
}
Cloud Natural Language API: Qwik Start
Cloud Natural Language API features
Syntax Analysis : 토큰과 문장을 추출하고, 말의 일부를 식별(PoS), create dependency parse trees for each sentence.
Entity Recognition : 개인, 조직, 위치, 이벤트, 제품 및 매체 등의 유형별로 엔티티와 레이블을 식별한다.
Sentiment Analysis : 텍스트 블록으로 표현된 전반적인 감정을 이해한다.
Content Classification : 사전에 정의된 700개 이상의 카테고리로 문서를 분류한다.
Multi-Language : 영어, 스페인어, 일본어, 중국어(간체 및 전통), 프랑스어, 독일어, 이탈리아어, 한국어, 포르투갈어를 포함한 여러 언어로 텍스트를 쉽게 분석할 수 있다.
Integrated REST API : REST API를 통한 액세스 텍스트는 요청에 업로드하거나 구글 클라우드 스토리지와 통합할 수 있다.
이 실습에서는 analyze-entities 방법을 사용하여 Cloud Natural Language API에 텍스트의 일부에서 “entities”(예: 사람, 장소, 이벤트)을 추출하도록 요청한다.
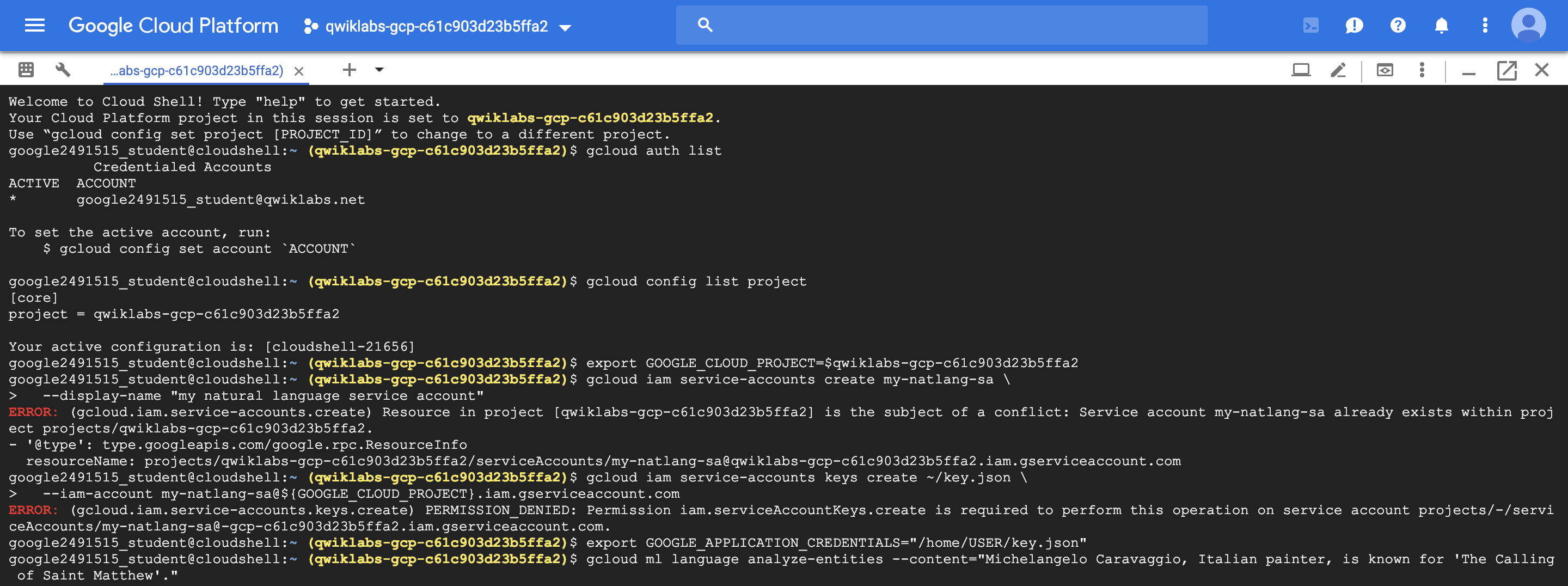
- “Michelangelo Caravaggio, Italian painter, is known for ‘The Calling of Saint Matthew’.” 문장에 대한 entity analysis 결과
name: 개체 이름 (전체 텍스트 중 분석 대상이 된 부분 문자열)
type: PERSON / LOCATION / EVENT
metadata: 연관된 위키피디아 정보
salience: 전체 텍스트 중 이 개체의 중요도(max 1.0)
mentions: 전체 텍스트 중 이 개체와 동일한 개체가 발견된 다른 지점(index)에 대한 정보 목록
{
"entities": [
{
"mentions": [
{
"text": {
"beginOffset": 0,
"content": "Michelangelo Caravaggio"
},
"type": "PROPER"
},
{
"text": {
"beginOffset": 33,
"content": "painter"
},
"type": "COMMON"
}
],
"metadata": {
"mid": "/m/020bg",
"wikipedia_url": "https://en.wikipedia.org/wiki/Caravaggio"
},
"name": "Michelangelo Caravaggio",
"salience": 0.82904786,
"type": "PERSON"
},
{
"mentions": [
{
"text": {
"beginOffset": 25,
"content": "Italian"
},
"type": "PROPER"
}
],
"metadata": {
"mid": "/m/03rjj",
"wikipedia_url": "https://en.wikipedia.org/wiki/Italy"
},
"name": "Italian",
"salience": 0.13981608,
"type": "LOCATION"
},
{
"mentions": [
{
"text": {
"beginOffset": 56,
"content": "The Calling of Saint Matthew"
},
"type": "PROPER"
}
],
"metadata": {
"mid": "/m/085_p7",
"wikipedia_url": "https://en.wikipedia.org/wiki/The_Calling_of_St_Matthew_(Caravaggio)"
},
"name": "The Calling of Saint Matthew",
"salience": 0.031136045,
"type": "EVENT"
}
],
"language": "en"
}
“À partager pour les jeunes étudiants de votre entourage ..Merci.” 문장에 대한 entity analysis 결과
{
"entities": [
{
"mentions": [
{
"text": {
"beginOffset": 48,
"content": "entourage"
},
"type": "COMMON"
}
],
"metadata": {},
"name": "entourage",
"salience": 0.55340046,
"type": "PERSON"
},
{
"mentions": [
{
"text": {
"beginOffset": 28,
"content": "\u00e9tudiants"
},
"type": "COMMON"
}
],
"metadata": {},
"name": "\u00e9tudiants",
"salience": 0.44659957,
"type": "PERSON"
}
],
"language": "fr"
}
Speech to Text Transcription with the Cloud Speech API
- 첫번째 실습과 유사하나 url링크, 분석 방법에 차이가 있다.
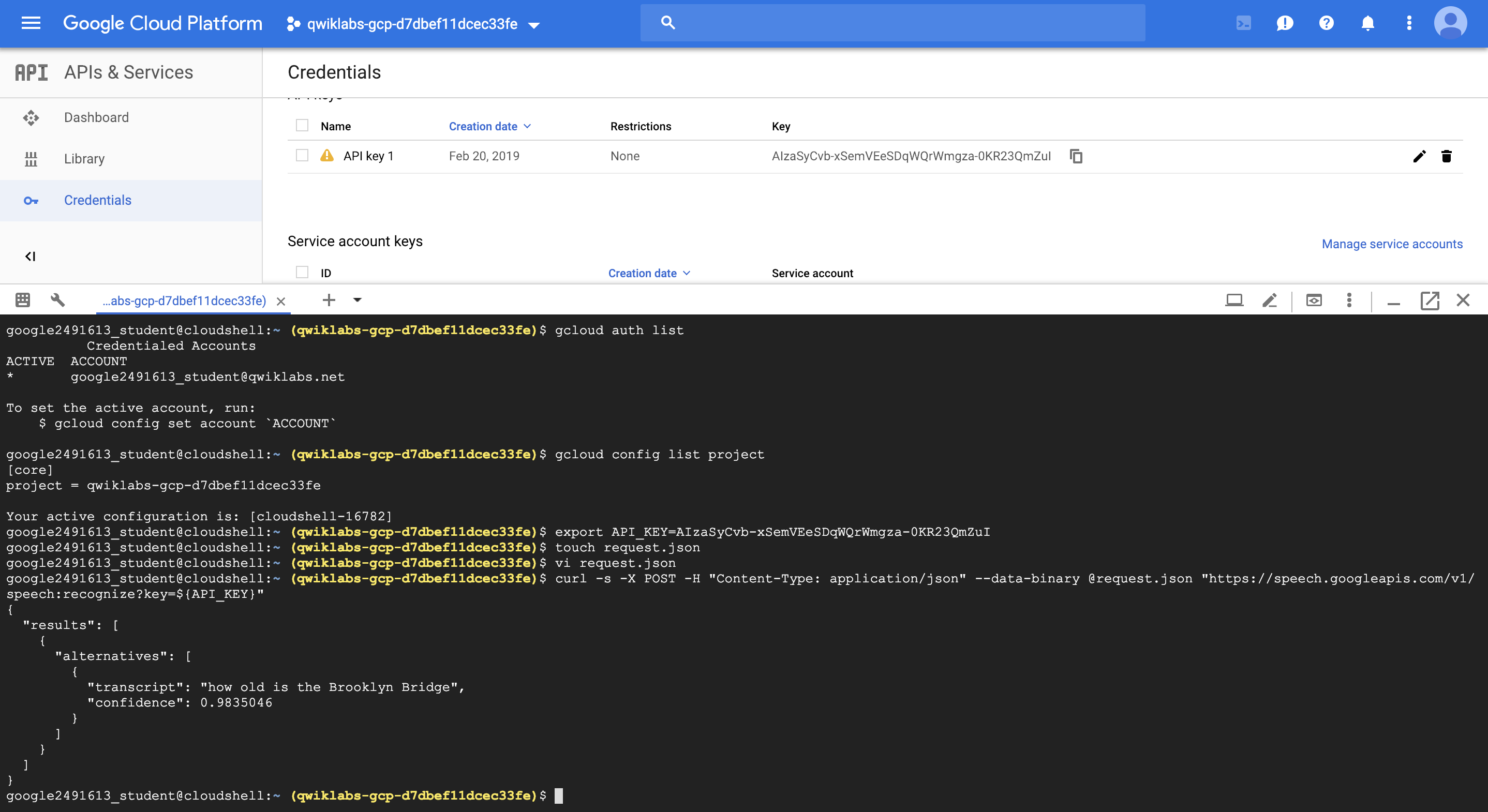

$vi request.json
에 해당하는 내용은 아래와 같다.
{
"config": {
"encoding":"FLAC",
"languageCode": "en-US"
},
"audio": {
"uri":"gs://cloud-samples-tests/speech/brooklyn.flac"
}
}
encoding: 오디오 파일 형식
language_code: 변환 대상의 언어
ex) 한국어: “ko-KR”, 프랑스어: “fr”
위의 음성 url 과 언어를 계속 바꿔주면서 test해 볼 수 있다. 정확도는 정말 많이 정확하다! (위의 두 예제 98% / 96%)
Entity and Sentiment Analysis with the Natural Language API
- 텍스트에서 엔티티를 추출, 정서와 품사 분석을 수행, 텍스트를 범주로 분류할 수 있는 API이다.
Entity Analysis Request (analyzeEntities)
$ curl "https://language.googleapis.com/v1/documents:analyzeEntities?key=${API_KEY}" \
-s -X POST -H "Content-Type: application/json" --data-binary @request.json
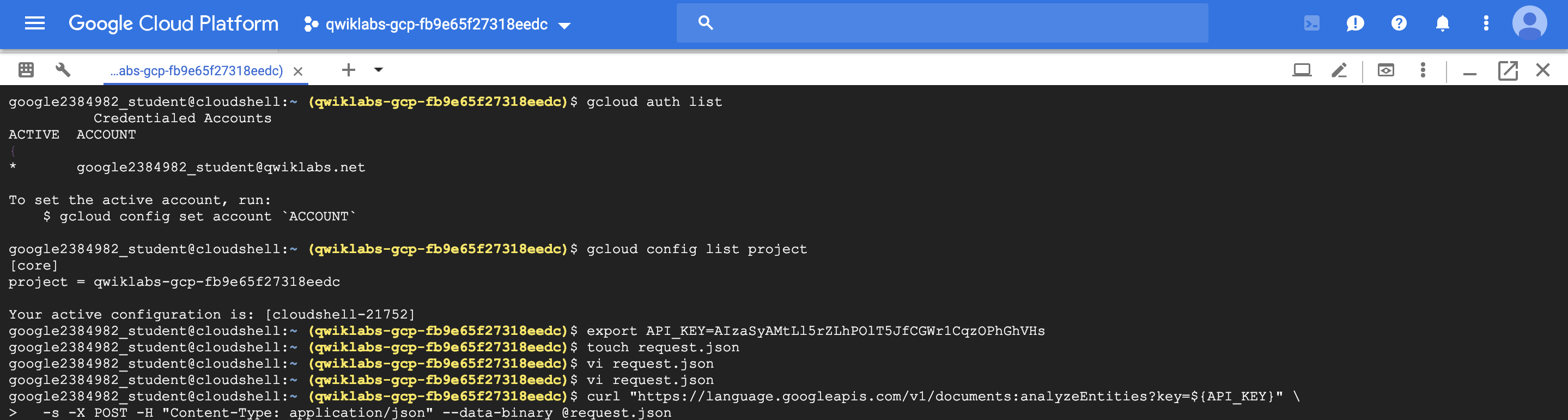
{
"document":{
"type":"PLAIN_TEXT",
"content":"Joanne Rowling, who writes under the pen names J. K. Rowling and Robert Galbraith, is a British novelist and screenwriter who wrote the Harry Potter fantasy series."
},
"encodingType":"UTF8"
}
name: 개체 이름 (전체 텍스트 중 분석 대상이 된 부분 문자열)
type: PERSON / LOCATION / EVENT
metadata: 연관된 위키피디아 정보
salience: 전체 텍스트 중 이 개체의 중요도(max 1.0)
mentions: 전체 텍스트 중 이 개체와 동일한 개체가 발견된 다른 지점(index)에 대한 정보 목록
{
"entities": [
{
"name": "Robert Galbraith",
"type": "PERSON",
"metadata": {
"mid": "/m/042xh",
"wikipedia_url": "https://en.wikipedia.org/wiki/J._K._Rowling"
},
"salience": 0.7980405,
"mentions": [
{
"text": {
"content": "Joanne Rowling",
"beginOffset": 0
},
"type": "PROPER"
},
{
"text": {
"content": "Rowling",
"beginOffset": 53
},
"type": "PROPER"
},
{
"text": {
"content": "novelist",
"beginOffset": 96
},
"type": "COMMON"
},
{
"text": {
"content": "Robert Galbraith",
"beginOffset": 65
},
"type": "PROPER"
}
]
},
...
]
}
Sentiment analysis with the Natural Language API
예시1) “Harry Potter is the best book. I think everyone should read it.”
{ "document":{ "type":"PLAIN_TEXT", "content":"Harry Potter is the best book. I think everyone should read it." }, "encodingType": "UTF8" }
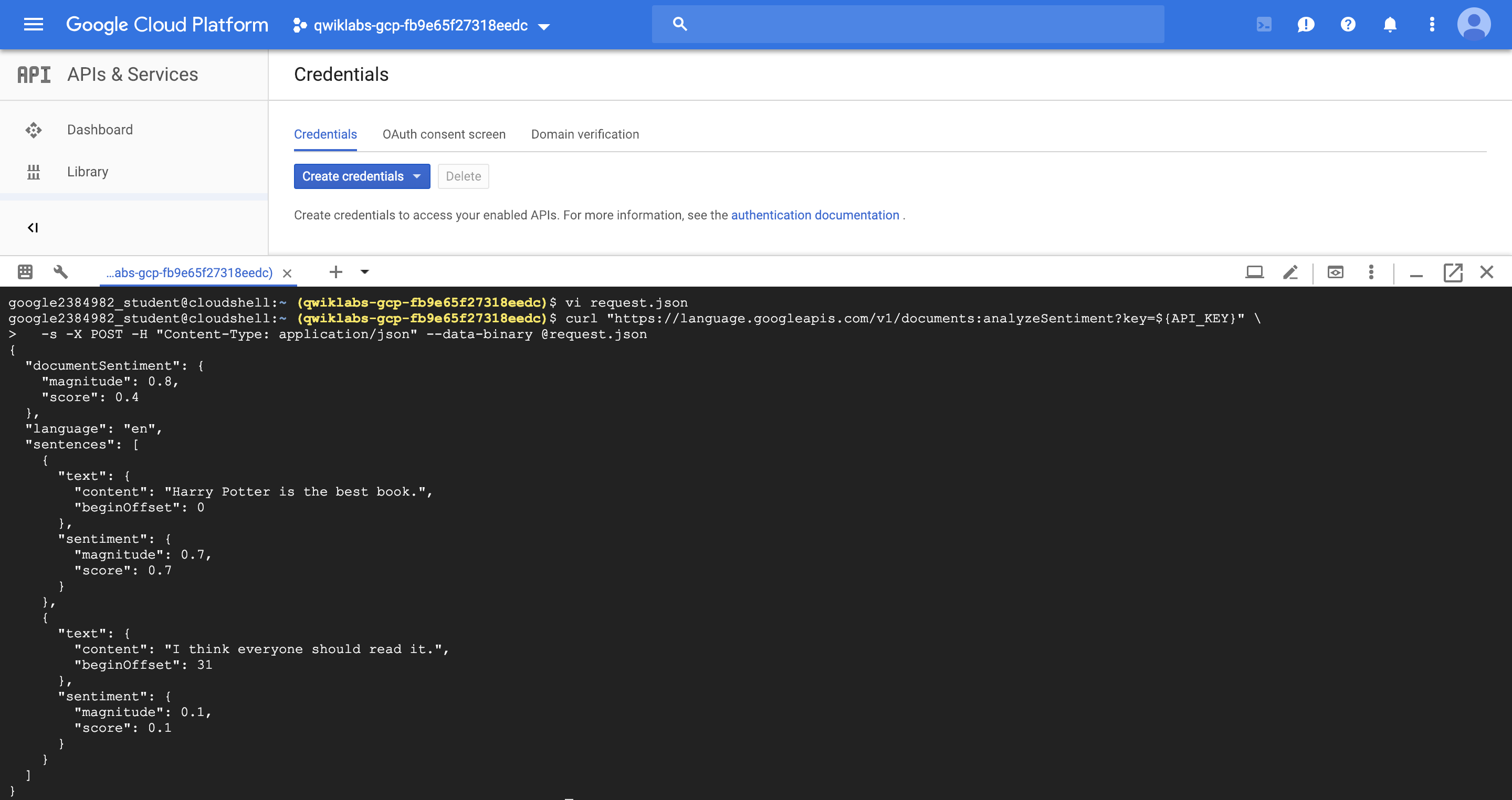
sentences : 문장단위로 분석
magnitude: 감정 (부정/긍정/중립)에 대한 강도 (0~∞)
score : 감정분석 점수 (-1~1 사이의 값)
{
"documentSentiment": {
"magnitude": 0.8,
"score": 0.4
},
"language": "en",
"sentences": [
{
"text": {
"content": "Harry Potter is the best book.",
"beginOffset": 0
},
"sentiment": {
"magnitude": 0.7,
"score": 0.7
}
},
{
"text": {
"content": "I think everyone should read it.",
"beginOffset": 31
},
"sentiment": {
"magnitude": 0.1,
"score": 0.1
}
}
]
}
Analyzing entity sentiment (analyzeEntitySentiment)
예시) I liked the sushi but the service was terrible.
{ "document":{ "type":"PLAIN_TEXT", "content":"I liked the sushi but the service was terrible." }, "encodingType": "UTF8" }
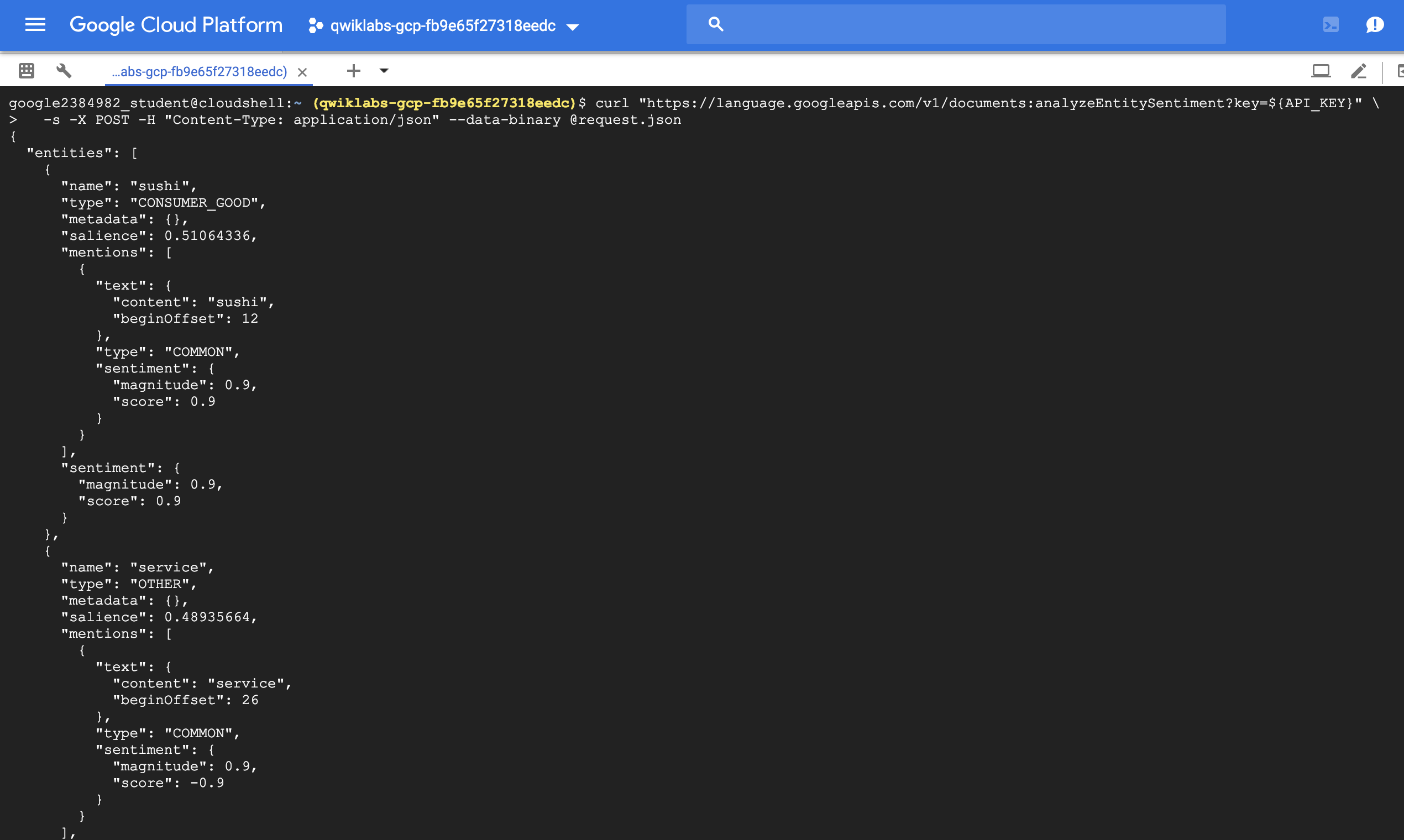
{
"entities": [
{
"name": "sushi",
"type": "CONSUMER_GOOD",
"metadata": {},
"salience": 0.52716845,
"mentions": [
{
"text": {
"content": "sushi",
"beginOffset": 12
},
"type": "COMMON",
"sentiment": {
"magnitude": 0.9,
"score": 0.9
}
}
],
"sentiment": {
"magnitude": 0.9,
"score": 0.9
}
},
{
"name": "service",
"type": "OTHER",
"metadata": {},
"salience": 0.47283158,
"mentions": [
{
"text": {
"content": "service",
"beginOffset": 26
},
"type": "COMMON",
"sentiment": {
"magnitude": 0.9,
"score": -0.9
}
}
],
"sentiment": {
"magnitude": 0.9,
"score": -0.9
}
}
],
"language": "en"
}
Analyzing syntax and parts of speech (analyzeSyntax)
$ curl "https://language.googleapis.com/v1/documents:analyzeSyntax?key=${API_KEY}" \ -s -X POST -H "Content-Type: application/json" --data-binary @request.json예시) “Joanne Rowling is a British novelist, screenwriter and film producer.”
{ "document":{ "type":"PLAIN_TEXT", "content": "Joanne Rowling is a British novelist, screenwriter and film producer." }, "encodingType": "UTF8" }
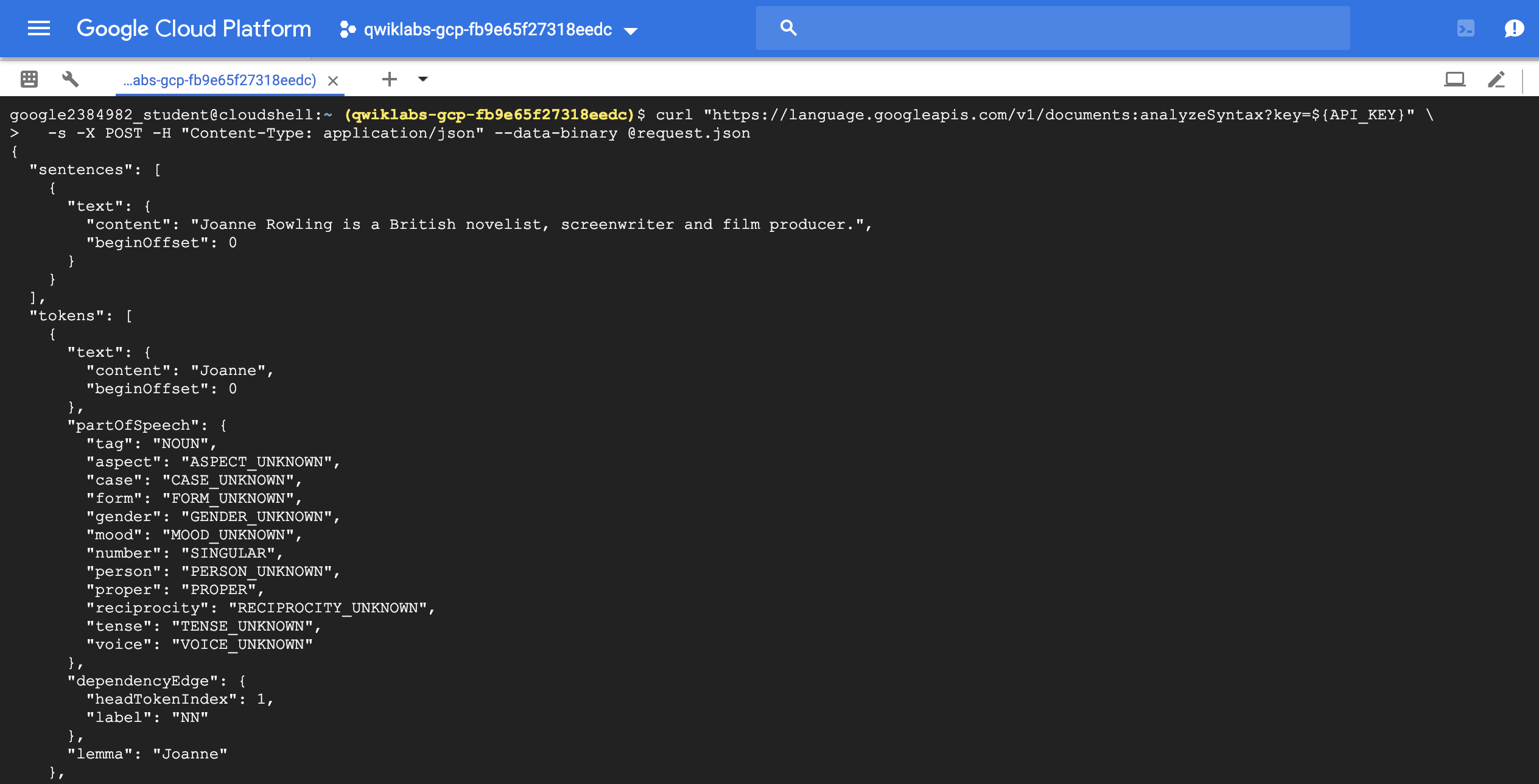
{
"text": {
"content": "is",
"beginOffset": 15
},
"partOfSpeech": {
"tag": "VERB",
"aspect": "ASPECT_UNKNOWN",
"case": "CASE_UNKNOWN",
"form": "FORM_UNKNOWN",
"gender": "GENDER_UNKNOWN",
"mood": "INDICATIVE",
"number": "SINGULAR",
"person": "THIRD",
"proper": "PROPER_UNKNOWN",
"reciprocity": "RECIPROCITY_UNKNOWN",
"tense": "PRESENT",
"voice": "VOICE_UNKNOWN"
},
"dependencyEdge": {
"headTokenIndex": 2,
"label": "ROOT"
},
"lemma": "be"
},

Multilingual natural language processing
예시1) 日本のグーグルのオフィスは、東京の六本木ヒルズにあります
- analyzeEntities
$ curl "https://language.googleapis.com/v1/documents:analyzeEntities?key=${API_KEY}" \ -s -X POST -H "Content-Type: application/json" --data-binary @request.json
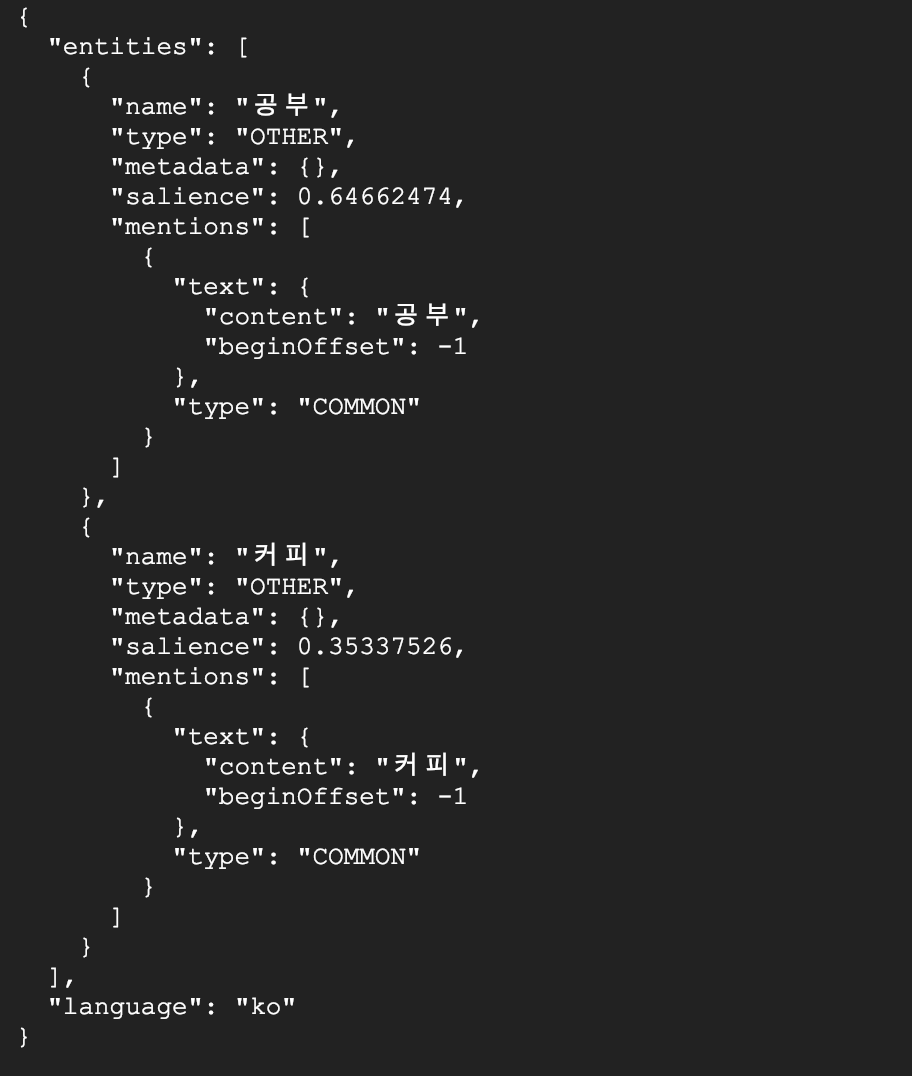
예시2) 나는 커피를 마시면서 공부를 시작했다. 오늘은 행복한 하루이다.
$ curl "https://language.googleapis.com/v1/documents:analyzeEntities?key=${API_KEY}" \
-s -X POST -H "Content-Type: application/json" --data-binary @request.json
$ curl "https://language.googleapis.com/v1/documents:analyzeSyntax?key=${API_KEY}" \
-s -X POST -H "Content-Type: application/json" --data-binary @request.json
{
"sentences": [
{
"text": {
"content": "나는 커피를 마시면서 공부를 시작했다.",
"beginOffset": -1
}
},
{
"text": {
"content": "오늘은 행복한 하루이다.",
"beginOffset": -1
}
}
],
"tokens": [
{
"text": {
"content": "나",
"beginOffset": -1
},
"partOfSpeech": {
"tag": "PRON",
"aspect": "ASPECT_UNKNOWN",
"case": "CASE_UNKNOWN",
"form": "FORM_UNKNOWN",
"gender": "GENDER_UNKNOWN",
"mood": "MOOD_UNKNOWN",
"number": "NUMBER_UNKNOWN",
"person": "FIRST",
"proper": "NOT_PROPER",
"reciprocity": "RECIPROCITY_UNKNOWN",
"tense": "TENSE_UNKNOWN",
"voice": "VOICE_UNKNOWN"
},
"dependencyEdge": {
"headTokenIndex": 7,
"label": "NSUBJ"
},
"lemma": "나"
},
{
"text": {
"content": "는",
"beginOffset": -1
},
{
"text": {
"content": "는",
"beginOffset": -1
},
"partOfSpeech": {
"tag": "PRT",
"aspect": "ASPECT_UNKNOWN",
"case": "NOMINATIVE",
"form": "FORM_UNKNOWN",
"gender": "GENDER_UNKNOWN",
"mood": "MOOD_UNKNOWN",
"number": "NUMBER_UNKNOWN",
"person": "PERSON_UNKNOWN",
"proper": "NOT_PROPER",
"reciprocity": "RECIPROCITY_UNKNOWN",
"tense": "TENSE_UNKNOWN",
"voice": "VOICE_UNKNOWN"
},
"dependencyEdge": {
"headTokenIndex": 0,
"label": "PRT"
},
"lemma": "는"
},
{
"text": {
"content": "커피",
"beginOffset": -1
},
"partOfSpeech": {
"tag": "NOUN",
"aspect": "ASPECT_UNKNOWN",
"case": "CASE_UNKNOWN",
"form": "FORM_UNKNOWN",
"gender": "GENDER_UNKNOWN",
"mood": "MOOD_UNKNOWN",
"number": "NUMBER_UNKNOWN",
"person": "PERSON_UNKNOWN",
"proper": "NOT_PROPER",
"reciprocity": "RECIPROCITY_UNKNOWN",
"tense": "TENSE_UNKNOWN",
"voice": "VOICE_UNKNOWN"
},
"dependencyEdge": {
"headTokenIndex": 4,
"label": "DOBJ"
},
"lemma": "커피"
},
{
"text": {
"content": "를",
"beginOffset": -1
},
"partOfSpeech": {
"tag": "PRT",
"aspect": "ASPECT_UNKNOWN",
"case": "ACCUSATIVE",
"form": "FORM_UNKNOWN",
"gender": "GENDER_UNKNOWN",
"mood": "MOOD_UNKNOWN",
"number": "NUMBER_UNKNOWN",
"person": "PERSON_UNKNOWN",
"proper": "NOT_PROPER",
"reciprocity": "RECIPROCITY_UNKNOWN",
"tense": "TENSE_UNKNOWN",
"voice": "VOICE_UNKNOWN"
},
"dependencyEdge": {
"headTokenIndex": 2,
"label": "PRT"
},
"lemma": "를"
},
{
"text": {
"content": "마시면서",
"beginOffset": -1
},
"partOfSpeech": {
"tag": "VERB",
"aspect": "ASPECT_UNKNOWN",
"case": "CASE_UNKNOWN",
"form": "COMPLEMENTIZER",
"gender": "GENDER_UNKNOWN",
"mood": "MOOD_UNKNOWN",
"number": "NUMBER_UNKNOWN",
"person": "PERSON_UNKNOWN",
"proper": "NOT_PROPER",
"reciprocity": "RECIPROCITY_UNKNOWN",
"tense": "TENSE_UNKNOWN",
"voice": "VOICE_UNKNOWN"
},
"dependencyEdge": {
"headTokenIndex": 7,
"label": "ADVCL"
},
"lemma": "마시면서"
},
...
