Matrix Factorization
in Data on Recommendation System
Recommendation System_Day4
- DAY4 _ Matrix 형태로 정의된 데이터를 이해하고 Matrix Factorization에 익숙해지기
- 각 본문의 출처는 제목 링크와 같습니다.
- 각 본문에서 필요하다고 생각되는 부분을 뽑아 정리한 자료입니다.
Coursera 16-5 Vectorization Low Rank Matrix Factorization (8:27)
Vectorization implementation of this algorithm
이 알고리즘으로 다른 무엇을 할 수 있는지 알아보자.
연관규칙 ( Association rule) (장바구니 규칙) _ 어떤 사람이 한 제품을 샀을 때 이것과 관련된 어떤 다른 제품을 추천해 줄 수 있는가
For example, one of the things you can do is, given one product can you find other products that are related to this so that for example, a user has recently been looking at one product. Are there other related products that you could recommend to this user?
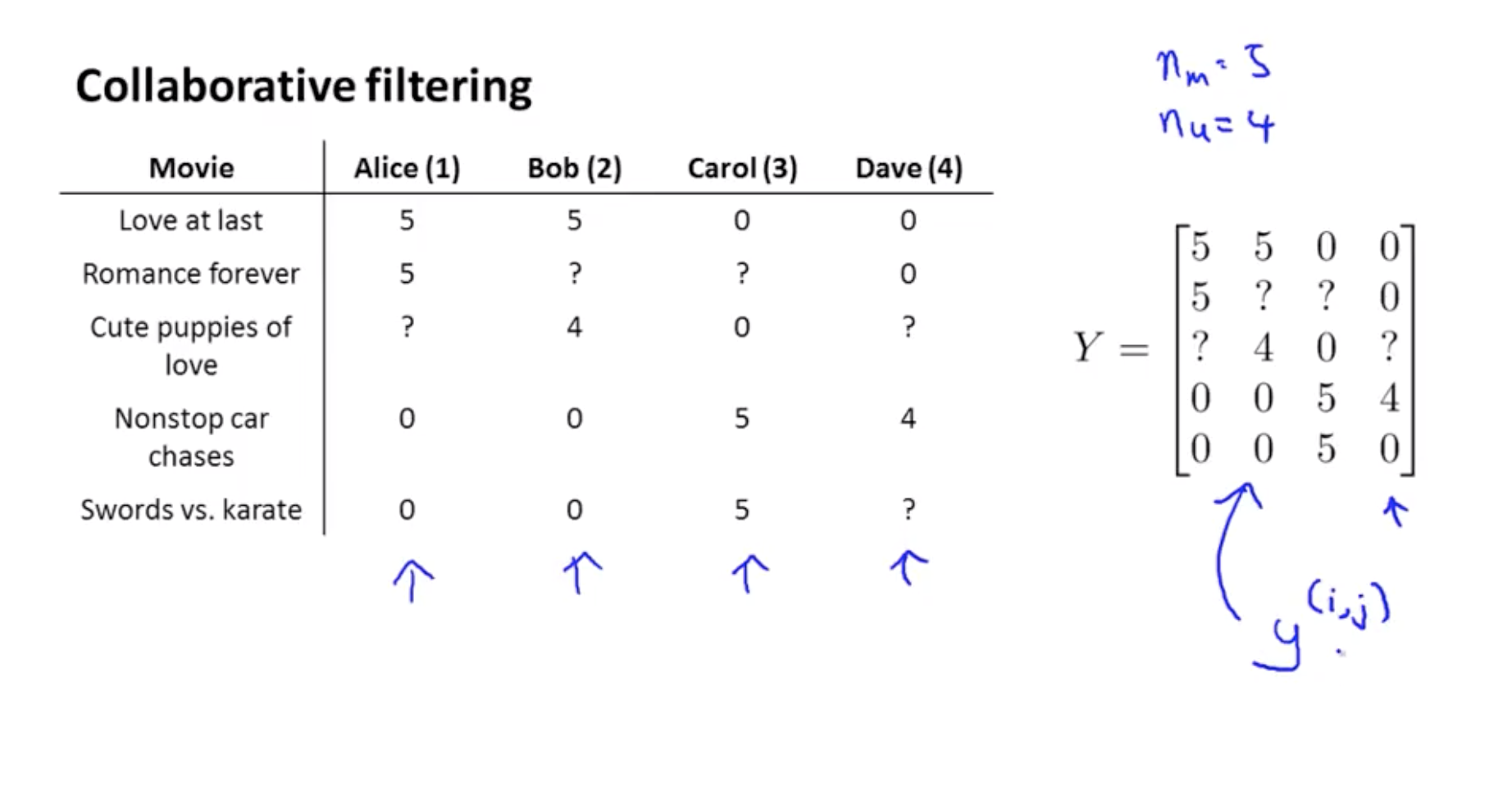 Y = data matrix
Y = data matrix
y(i,j) = Y의 (i,j) 원소

(θ(2))Tx(1) : 영화 1에 대한 user 2의 rating
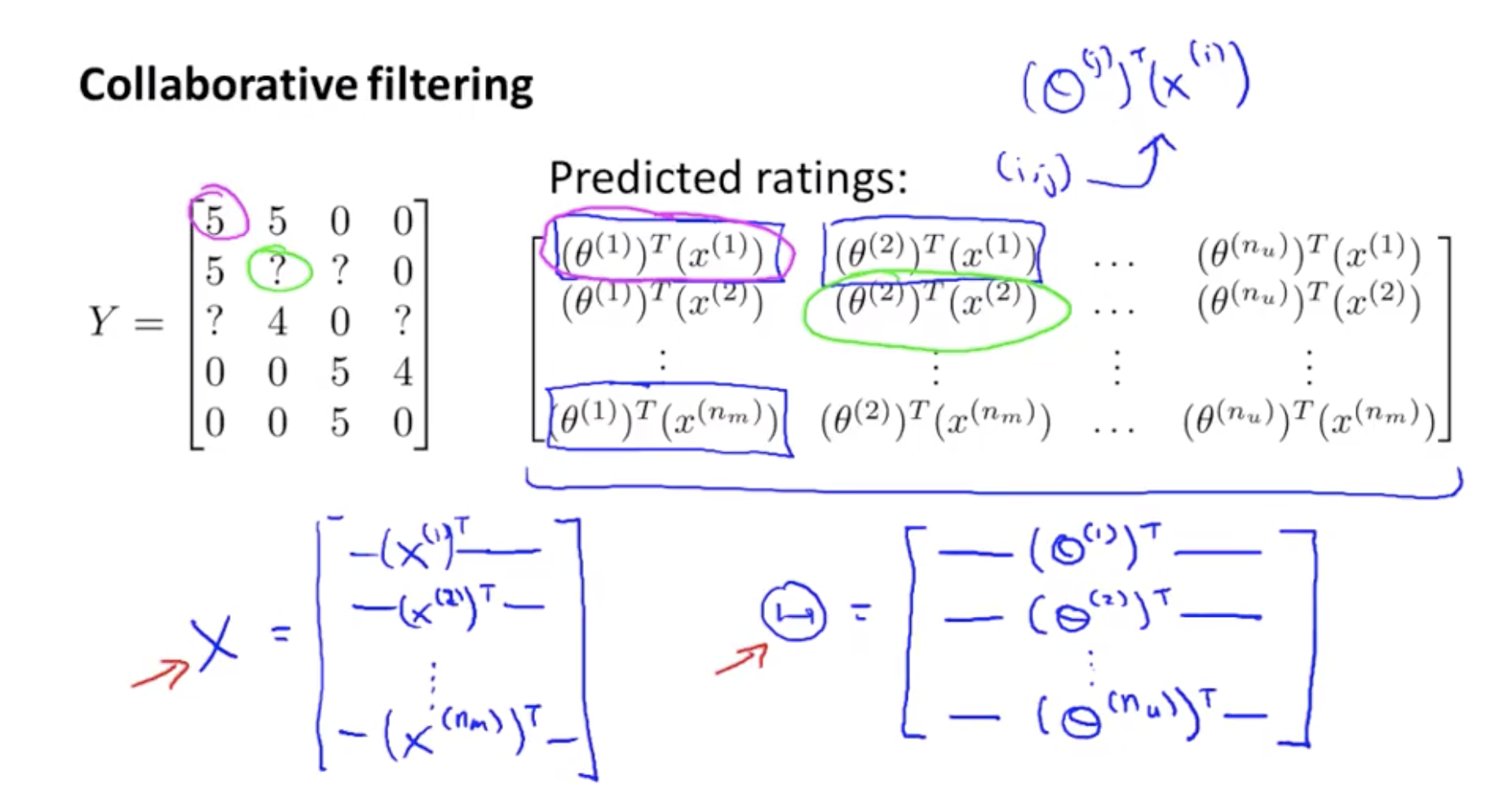
- X와 Θ의 표현법.
- 최종적으로 Notation은 XΘT 이 된다.
Collaborative filtering 의 다른 이름은 low rank matrix factorization이다
*low rank matrix facorization : 모든 matrix는 다른 두 matrix의 곱으로 표현이 가능하다. 이때 만약 matrix의 rank가 작다면 두 matrix 의 rank역시 더 작은 형태로 표현이 가능하게 된다. 즉, 원래 n*m matrix R이 n이나 m보다 작은 k만큼의 rank를 가졌을 때, R은 n*k matrix P와 m*k matrix Q의 곱으로 표현할 수 있다. 즉, R=PQT으로 표현이 된다는 사실이 알려져있다.출처
 collaborative filtering 알고리즘을 이용하여 학습된 feature들로 관련된 영화를 찾을 수 있다. 사람들이 실제로 각 feature들이 진짜 무엇인지 사람들이 판단하긴 힘들다. 하디만 그 feature들은 좋고 싫음을 유발하는 영화의 가장 중요하고 의미있는 성질들은 포착하여 학습될 것이다.
collaborative filtering 알고리즘을 이용하여 학습된 feature들로 관련된 영화를 찾을 수 있다. 사람들이 실제로 각 feature들이 진짜 무엇인지 사람들이 판단하긴 힘들다. 하디만 그 feature들은 좋고 싫음을 유발하는 영화의 가장 중요하고 의미있는 성질들은 포착하여 학습될 것이다.
- You can do which is use the learned features in order to find related movies.
- Usually, it will learn features that are very meaningful for capturing whatever are the most important or the most salient properties of a movie that causes you to like or dislike it.

영화 i 가 있고 이와 관련된 다른 영화 j 어떻게 찾을 수 있을까?
feature vector를 학습시켰으면, 얼마나 두 영화가 비슷한지 측정할 수 있는 매우 편리한 방법이 있다. 영화 i 는 feature vector x(i) 를 가지고 있을 것이고, 영화 j 의 feacture vector x(j) 와의 거리를 가장 작게하는 x(j) 를 찾으면 영화 i 와 관련된 영화 j를 찾을 수 있다.
5개 영화를 추천해 주고 싶다면 거리가 가장 작은순으로 5개의 영화를 추천해 주면 된다.
- Now that you have learned these feature vectors, this gives us a very convenient way to measure how similar two movies are.
- In particular, movie i has a feature vector xi. and so if you can find a different movie, j, so that the distance between xi and xj is small, then this is a pretty strong indication that, you know, movies j and i are somehow similar.
Coursera 16-6 Implementation Detail Mean Normalization (8:30)
Implementational Detail: Mean Normalization (성능향상을 위해 )
첫 이용자(Eve) 에게 어떻게 추천을 할 것인가. θ(5) 를 예측해보자.

n=2 (feature 수)
θ(5) 는 아무런 rating이 없으므로 squared error term = 0. 따라서 제일 끝에 있는 식만 영향을 미치고, 이는 결국 λ/2[(θ(5)1)2 + (θ(5)2)2 ] 를 minimize 하는 것과 같은 문제가 된다. 그런데 θ에 대해서 minimize하게 되면 결국 0으로 수렴하므로 θ(5) = [ 0 0 ]T 가 된다. 따라서 (θ(5))Txi = 0 (for any i) 가 된다. 하지만 이 값은 별로 유용해 보이지 않는다.
Mean Normalization 이러한 문제를 해결해 준다.

모든 이용자들의 rating을 grouping 하여 Y라고 하자.
이 matrix Y를 정규화 하는 것인데, 각 row의 평균을 구하여 μ vector를 구하고 Y 의 각 원소에 해당 row의 μ를 빼준다. 즉 Y’ = Y-μ 를 하여 Y’의 평균이 0이 되도록 한다. ; mean normalization

따라서 예측값은 (θ(j))Txi + μi 가 되고 θ(5) = 0 + μi = [ 2.5 2.5 2 2.25 1.25 ]T
즉, 신규 유저의 rating은 기존 user들의 평균으로 대체한다는 의미가 된다.
