Collaborative Filtering 문제 정의
in Data on Recommendation System
Recommendation System_Day3
- DAY3 _ Collaborative Filtering 문제 정의에 익숙해지기
- 각 본문의 출처는 제목 링크와 같습니다.
- 각 본문에서 필요하다고 생각되는 부분을 뽑아 정리한 자료입니다.
Coursera 16-3 Collaborative Filtering (10:14)
Contents based recommendation은 굉장히 비효율 적이다. 데이터 수가 많아지면 feature을 얻기에도 힘들다. 따라서 오늘은 feature x1, x2을 모른다고 가정하고 문제를 해결할 것이다. 그 전에 각 user들 에게서 그들의 취향을 얻어냈다고 가정해 보자.
- Suppose that we have a data set where we do not know the values of these features.
- Let’s say we’ve gone to each of our users, and each of our users has told has told us how much they like the romantic movies and how much they like action packed movies.
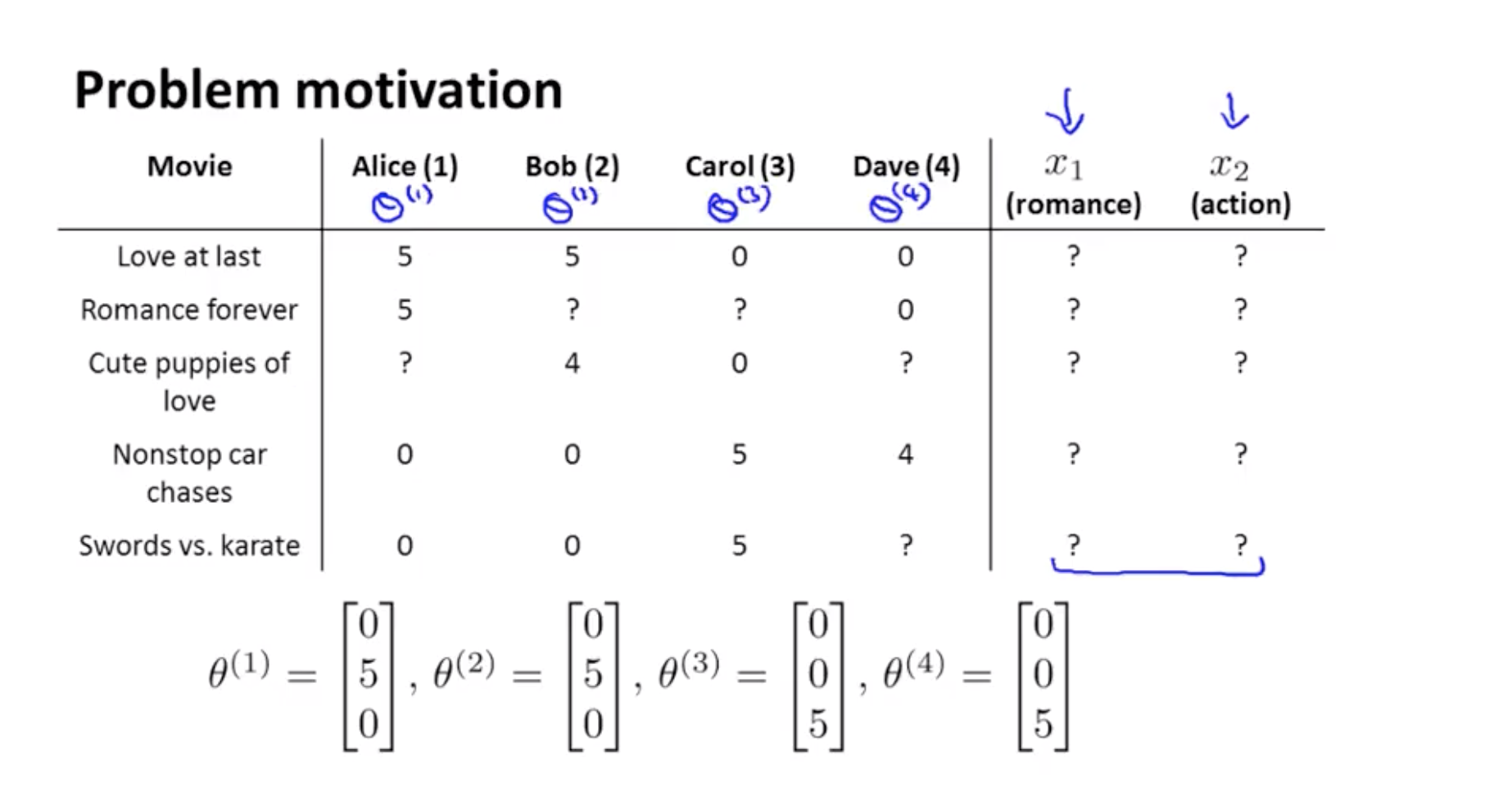
θ(j) : parameter vector. User의 선호도
θ(j) 를 안다고 가정하면 x1과 x2를 찾을 수 있다.
- If we can get these parameters theta from our users then it turns out that it becomes possible to try to infer what are the values of x1 and x2 for each movie.
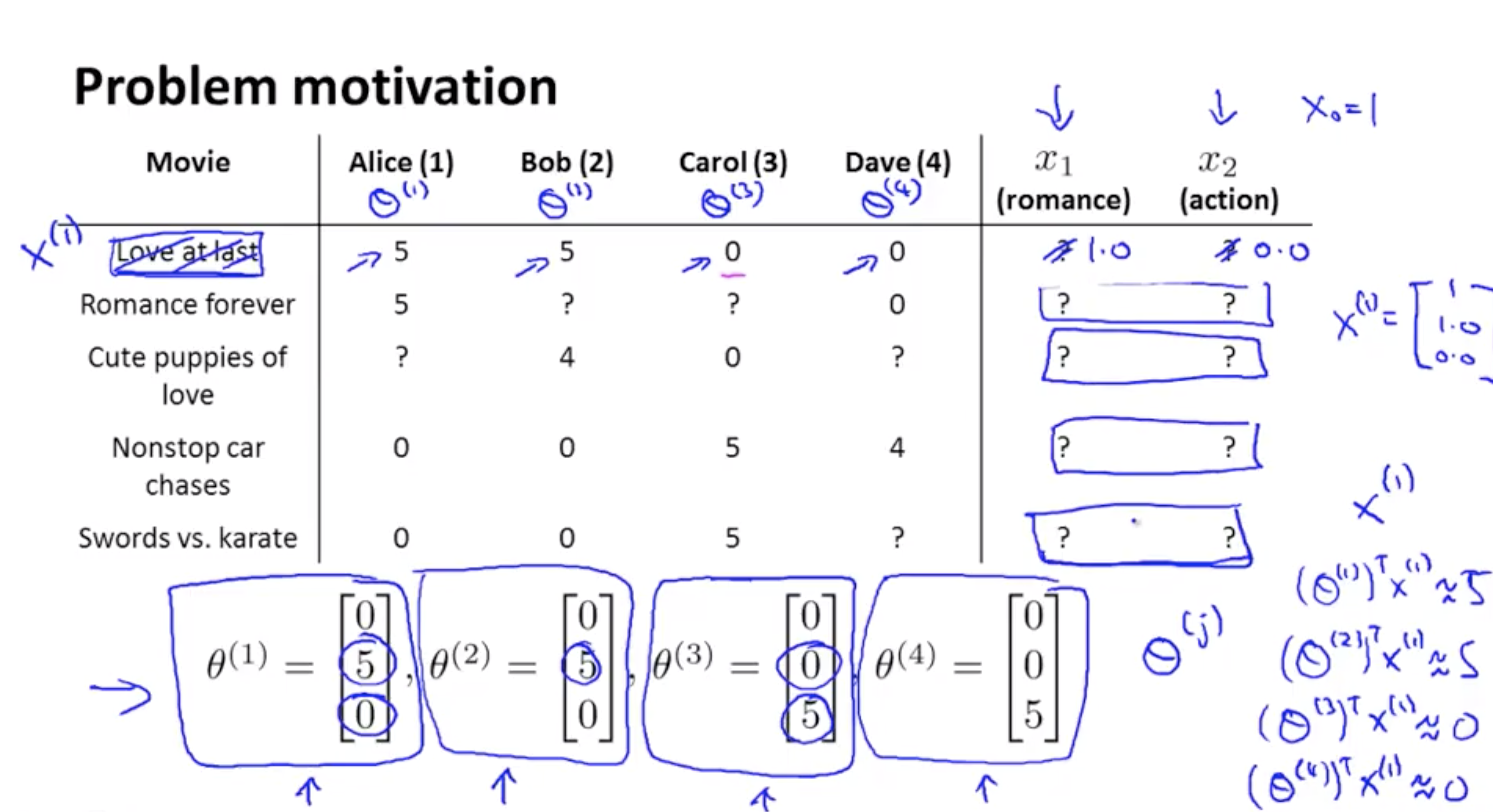
x(1) 영화제목 없다고 가정하고 user들이 준 θ(j) 만 보았을 때 다음을 만족하는 조건으로 x(1) 를 추측할 수 있다.
(θ(1))Tx(1) ~= 5
(θ(2))Tx(1) ~= 5
(θ(3))Tx(1) ~= 0
(θ(4))Tx(1) ~= 0
 i : movie index
i : movie index
j : user index
nu : user 의 수
nm : movie 의 수
r(i,j) : user들의 rating이 있으면 = 1 , 없으면 = 0
y(i,j) : r(i,j) = 1인 것 중에서 rating들을 나타낸 것 (0,…,5)
(θ(j))Tx(i) : predictied rating
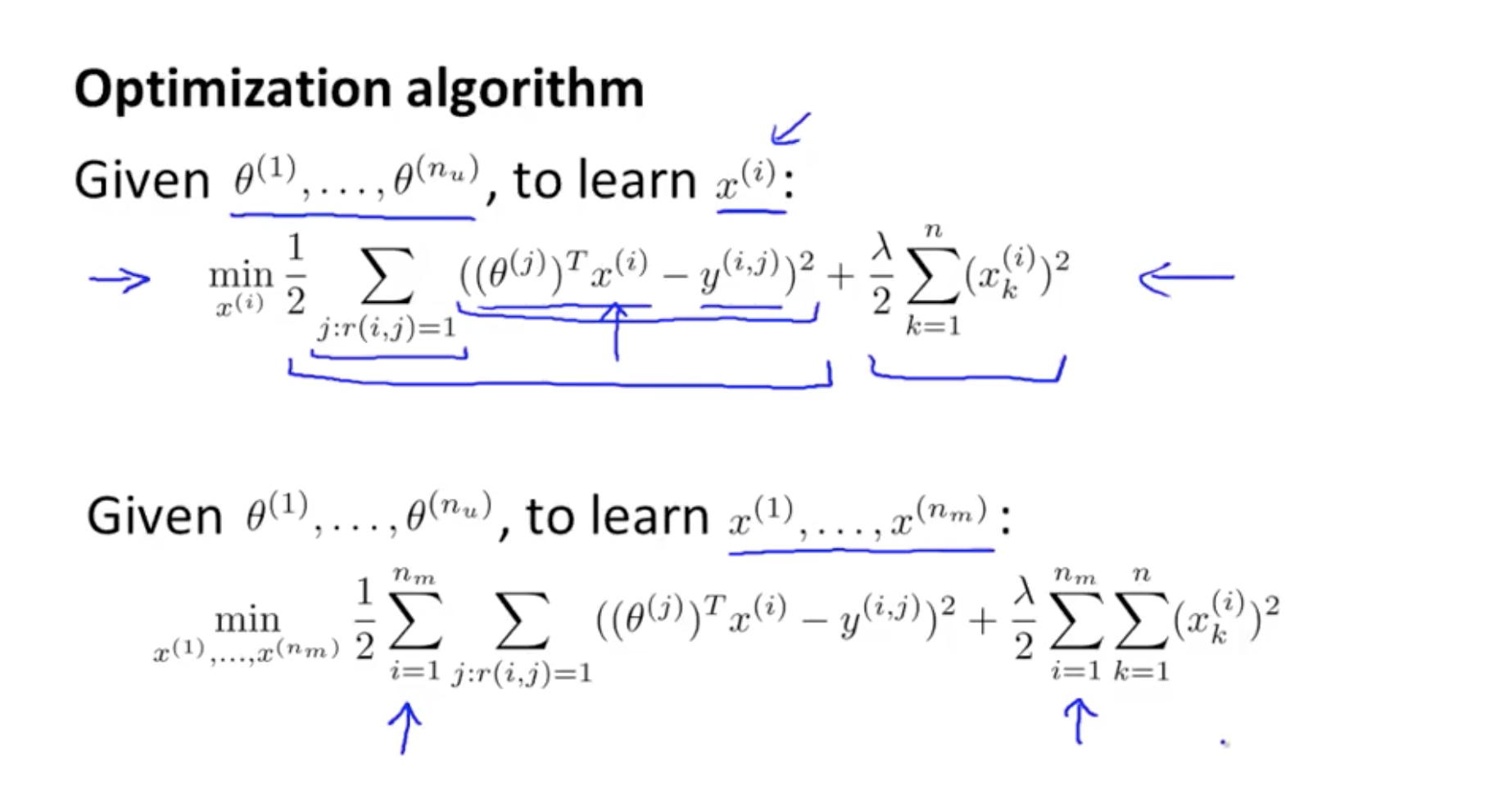
Sumension(예측값 ( (θ(j))Tx(i) ) - 실제값 ( y(i,j) ))^2 : MSE + regularization term (feature가 너무 커지지 않도록) 을 minimize하는 것이 x(j) 를 추정하는 Optimization objective이다.
위의 식을 minimize하면 x(j) 에 대한 꽤 좋은 추정치를 얻을 수 있다.
Basic collaborative filtering (협업 필터링)

y(i,j) , r(i,j) 가 주어졌을 때, feature vector를 알 때 parameter vector 를 추정할 수 있고 반대로 parameter vector를 알 때 feature vector을 추정할 수 있다.
각각 추정된 혹은 주어진 θ(j), x(j) 를 바탕으로 추정치를 더욱 향상 시킬 수 있고 이것이 collaborating filtering 알고리즘의 기본이다. (최종적으로 사용할 알고리즘은 아니다.)
또 이 알고리즘은 Recommendation system 에서만 사용가능한데, 각각의 유저가 여러 영화에 대해 평점을 매길 수 있고, 각각의 영화 역시 여러 유저들에 의해 평점이 매겨질 수 있기 때문이다.
Collaborative filtering은 큰 user set과 함께 쓰일 때, 모든 user에 대한 더 나은 rating을 위해 협력하는 것을 나타낸다.
- For this problem, for the recommender system problem, this is possible only because each user rates multiple movies and hopefully each movie is rated by multiple users.
- The term collaborative filtering refers to the observation that when you run this algorithm with a large set of users, what all of these users are effectively doing are sort of collaboratively–or collaborating to get better movie ratings for everyone because with every user rating some subset with the movies, every user is helping the algorithm a little bit to learn better features, and then by helping– by rating a few movies myself, I will be helping the system learn better features and then these features can be used by the system to make better movie predictions for everyone else.
Coursera 16-4 Collaborative Filtering Algorithm (8:26)
 랜덤하게 parameter을 초기화한 후 왔다갔다 하면서 풀 수 있을 것이다. (θ를 구하고 그걸 이용하여 x를 구하고, 또 θ를 구하고 … ) 하지만 θ와 x를 동시에 구할 수 있는 방법이 있다. 이건 기본적으로 위의 두 Optimization objective를 둘을 동일한 objective에 넣는 것이다.
랜덤하게 parameter을 초기화한 후 왔다갔다 하면서 풀 수 있을 것이다. (θ를 구하고 그걸 이용하여 x를 구하고, 또 θ를 구하고 … ) 하지만 θ와 x를 동시에 구할 수 있는 방법이 있다. 이건 기본적으로 위의 두 Optimization objective를 둘을 동일한 objective에 넣는 것이다.
But, it turns out that there is a more efficient algorithm that doesn’t need to go back and forth between the x’s and the thetas, but that can solve for theta and x simultaneously
What we are going to do, is basically take both of these optimization objectives, and put them into the same objective.

J는 두 개의 Optimization objective 을 합친 cost function이다.

θ(j)들을 추정하는 optimization objective와 x(j) 를 추정하는 optimization objective의 Sqaure error term 을 보면 식은 같지만 더하는 범위인 i, j만 다른 것을 볼 수 있다.
따라서 두 식을 합친다는 건 모든 i와 j에 대한 ((i,j)=1인 것들 중에서) 합이라는 것을 알 수 있다.
- So, this is really summing over all pairs IJ, that correspond to a movie that was rated by a user.Sum over J says, for every user, the sum of all the movies rated by that user.

J의 regularization term역시 각각의 regularization term 을 합친 것과 같다.
J를 보면 흥미로운 속성을 가지고 있는데, x의 constant들을 고정시키고 θ에 대해서만 minimize한다면 θ를 예측하는 optimization objective를 푸는 것과 동일한 문제가 되며 (x의 constant들을 고정시키면 x에 해당하는 regularization term이 0이 되므로) ,반대로 θ의 constant들을 고정시키고 x에 대해서만 minimize한다면 결국 x를 예측하는 optimization objective와 같아질 것이다. (θ의 constant들을 고정시키면 θ에 해당하는 regularization term이 0이 되므로)
- And this optimization objective j actually has an interesting property that if you were to hold the x’s constant and just minimize with respect to the thetas then you’d be solving exactly this problem, whereas if you were to do the opposite, if you were to hold the thetas constant, and minimize j only with respect to the x’s, then it becomes equivalent to this.

결론적으로 J를 Minimize 하는 red box부분을 구하는 것과 같은 문제가 된다
이전 알고리즘 (Day3 첫번째 강의의 collaborative filltering) 과 가장 큰 차이점은 θ를 minimize 하고, x를 minimize하고 이렇게 왔다 갔다 하면서 찾는 것 대신에 (순차적) parameter vector x와 θ를 동시에 minimize 한다는 것이다.
또한 이 J의 특징은 이전엔 x0 =1 이라는 intercept를 정의했었다면 이젠 intercept없이 실제 사용되는 feature들만 이용하기 때문에 x∈Rn 이 된다. (이전엔 x∈Rn+1 ) θ역시 θ∈Rn 이 된다. (x0 가 없다면 θ0 도 없기 때문). 이것이 가능한 이유는 이제 모든 feature들을 학습시키면서 x0 도 스스로 학습하여 선택할 수 있게끔 하기 때문이다. 따라서 k=0일 때의 조건 없이 동일한 식을 사용한다.
And really the only difference between this and the older algorithm is that, instead of going back and forth, previously we talked about minimizing with respect to theta then minimizing with respect to x, whereas minimizing with respect to theta, minimizing with respect to x and so on.
- In this new version instead of sequentially going between the 2 sets of parameters x and theta, what we are going to do is just minimize with respect to both sets of parameters simultaneously.
- Finally one last detail is that when we’re learning the features this way. Previously we have been using this convention that we have a feature x0 equals one that corresponds to an interceptor.
- And the reason we do away with this convention is because we’re now learning all the features, right? So there is no need to hard code the feature that is always equal to one. Because if the algorithm really wants a feature that is always equal to 1, it can choose to learn one for itself. So if the algorithm chooses, it can set the feature X1 equals 1. So there’s no need to hard code the feature of 001, the algorithm now has the flexibility to just learn it by itself. So, putting everything together, here is our collaborative filtering algorithm.

- x들과 θ들을 random value로 초기화 한다. (Neural network 과정이랑 조금 비슷하다)
- gradient descent를 이용해 cost function을 minimize 한다
- x(i)k = x(i)k - α (J를 x(i)k 에 대해서 편미분)
- θ(i)k = θ(i)k - α (J를 θ(i)k 에 대해서 편미분)
- user에게 받은 parameter θ, 학습된 feature x를 사용하여 rating (θ(j))Tx(i) 을 예측한다
이것이 바로 협업 필터링 알고리즘이며, 이 알고리즘을 구현하면 희망하는 모든 영화에 대한 좋은 feature 뿐만 아니라 모든 사용자에 대한 parameter를 학습하는 동시에, 서로 다른 user들이 어떻게 다른 영화를 rating하는지에 대한 꽤 괜찮은 예측을 할 수 있다.
- So that’s the collaborative filtering algorithm and if you implement this algorithm you actually get a pretty decent algorithm that will simultaneously learn good features for hopefully all the movies as well as learn parameters for all the users and hopefully give pretty good predictions for how different users will rate different movies that they have not yet rated.
