Recommendation과 Machine Learning의 Formulation
in Data on Recommendation System
Recommendation System_Day2
- DAY2 _ Recommendation과 Machine Learning의 Formulation에 익숙해지기
- 각 본문의 출처는 제목 링크와 같습니다.
- 각 본문에서 필요하다고 생각되는 부분을 뽑아 정리한 자료입니다.
Coursera 16-1 Problem Formulation (7:54)
Recommendation system이 중요한 이유
1) Important application of machine learning.
많은 실리콘밸리 기업들이 더 나은 추천시스템을 구축하려고 노력하고 있다.
ex) Amazon 의 과거 구입 책 기반 새로운 책 추천, Netflix의 과거 영화 평점 기반 새로운 영화 추천
이들은 아마존 수입의 상당한 부분을 차지하며 넷플릭스 역시 유저들을 새로운 영화로 끌어들이는데 상당한 부분을 차지한다. 따라서 추천시스템의 퍼포먼스 향상은 이들 회사에 실질적이고 즉각적인 영향을 끼친다.
Many groups out in Silicon Valley now, trying to build better recommender systems.
There are many websites or systems that try to recommend new products to use.
ex) Amazon recommends new books, Netflix recommends new movies.
These sorts of recommender systems, that look at what books you may have purchased in the past, or what movies you have rated in the past, but these are the systems that are responsiblefor today, a substantial fraction of Amazon’s revenue and for a company like Netflix, the recommendations that they make to the users is also responsible for a substantial fraction of the movies watched by their users. -> Improvement in performance of a recommender system can have a substantial and immediate impact on the bottom line of many of these companies.
2) feature의 중요성
우리가 고른 feature들이 알고리즘에 큰 영향을 끼칠 것이다. 머신러닝의 큰 아이디어는 이러한 feature고르는 문제를 자동화 해주는 것이다.
We’ve already seen in this class that features are important for machine learning, the features you choose will have a big effect on the performance of your learning algorithm.
- So there’s this big idea in machine learning, there are algorithms that can try to automatically learn a good set of features for you.
- There are a few settings where you might be able to have an algorithm, just to learn what feature to use, and the recommender systems is just one example of that sort of setting.
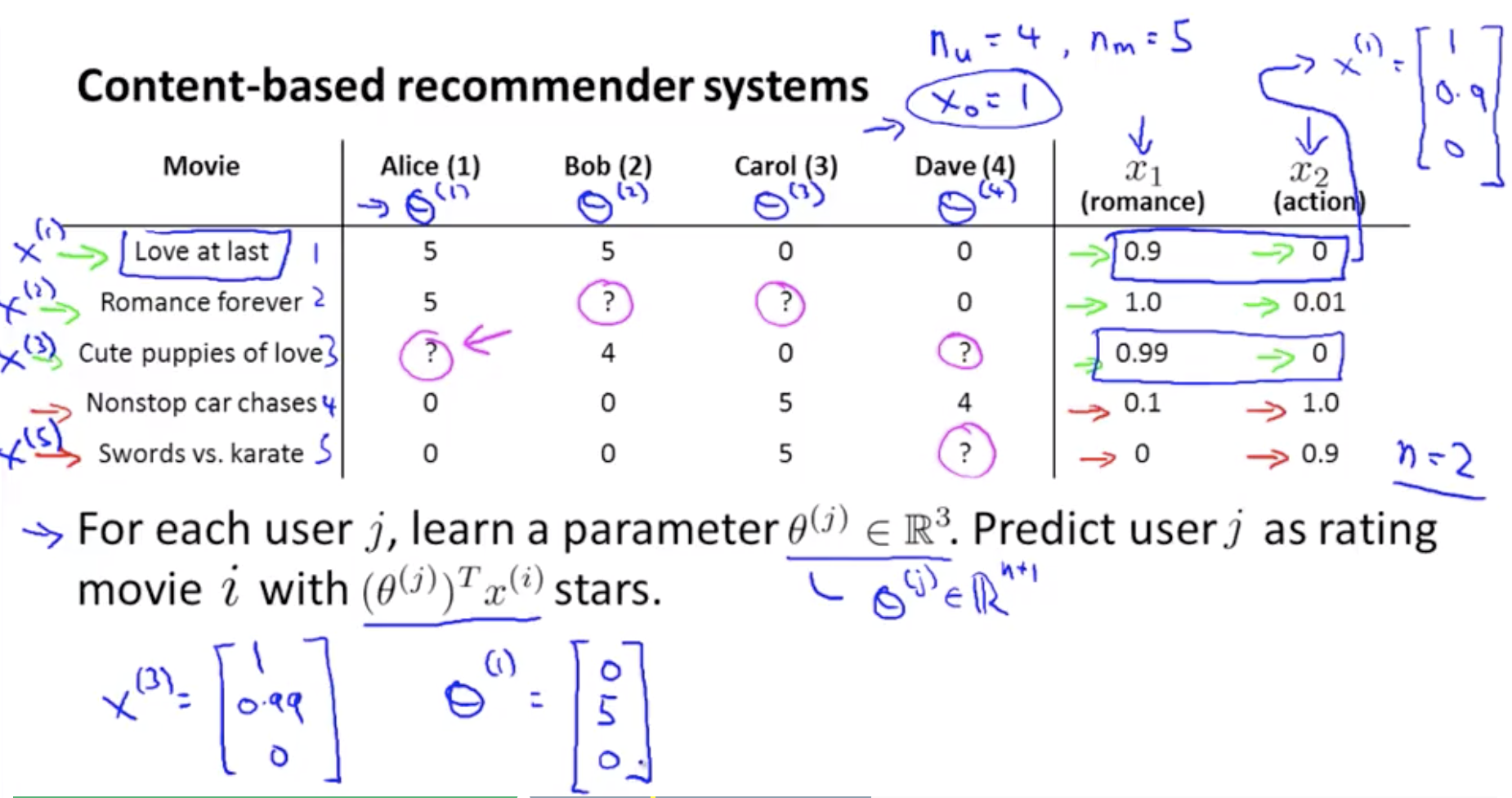
예제_ Predicting movie ratings
Romance : Love at last, Romance forever, Cute puppies of love
Action : Nonstop car chases, Swords vs. karate

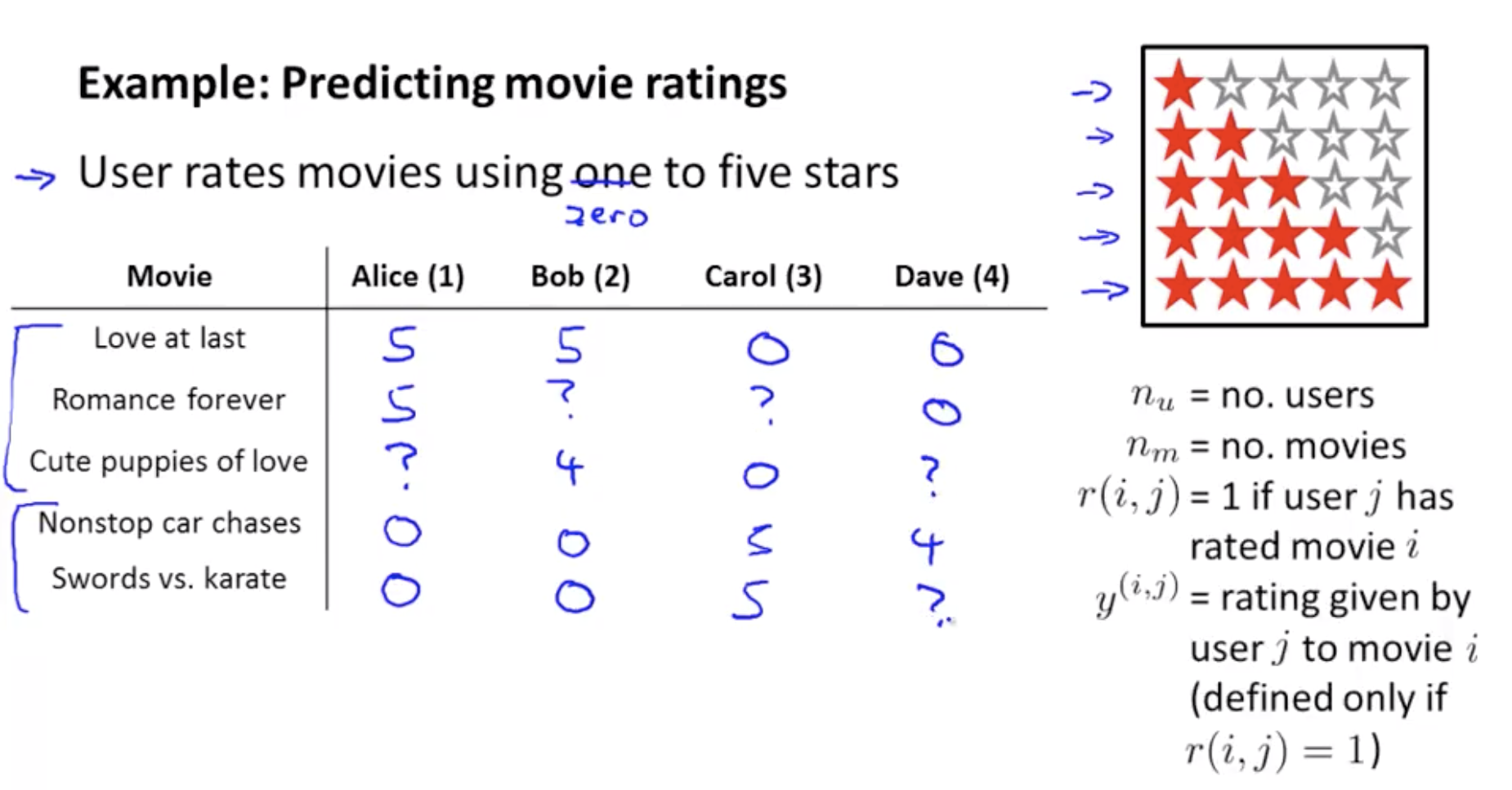
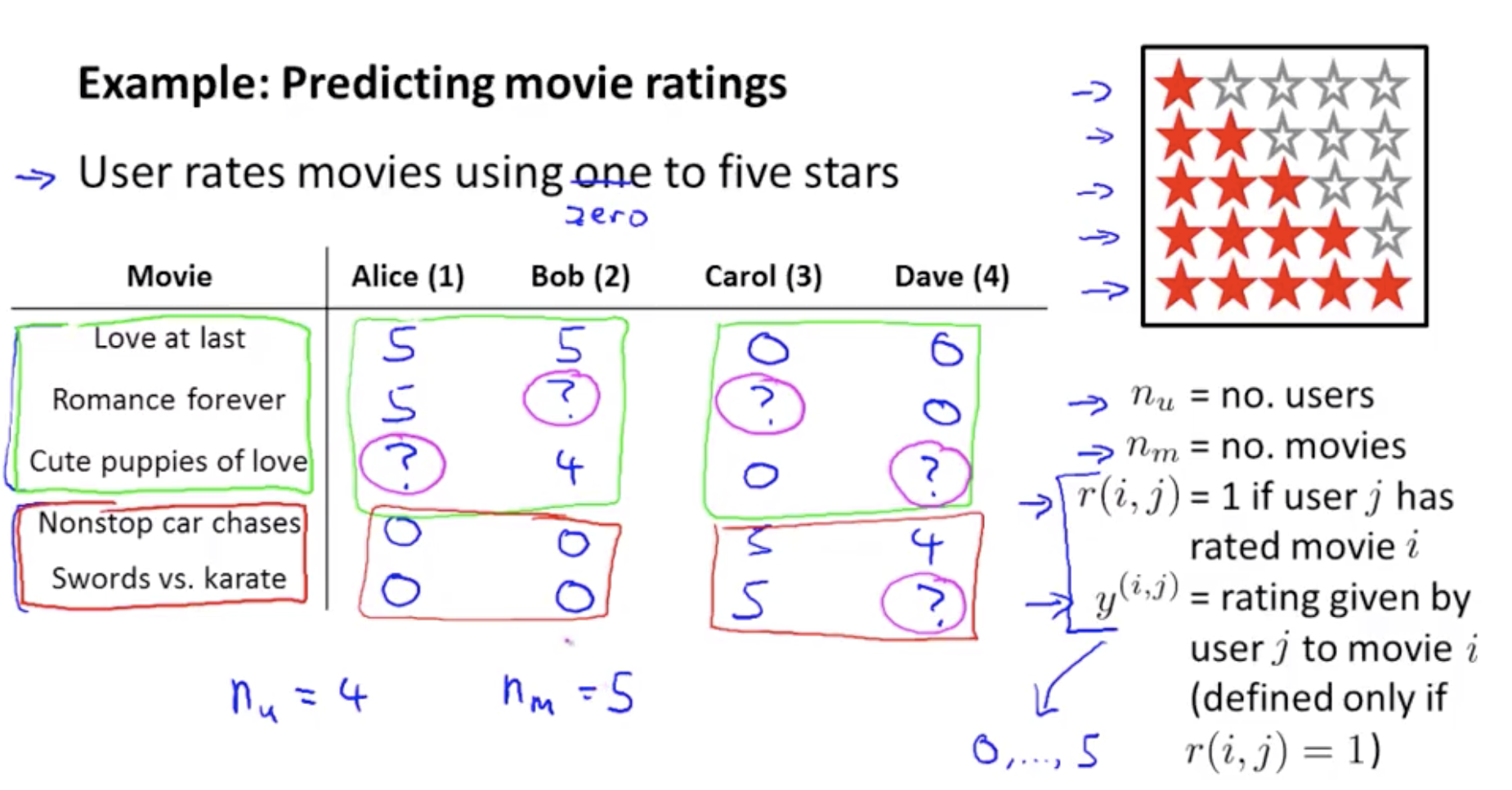
i : movie index
j : user index
nu : user 의 수
nm : movie 의 수
r(i,j) : user들의 rating이 있으면 = 1 , 없으면 = 0
y(i,j) : r(i,j) = 1인 것 중에서 rating들을 나타낸 것 (0,…,5)
추천시스템을 개발하는데 있어서 우리의 일은 우리가 이런 missing value를 자동으로 채울 수 있는 학습 알고리즘을 고안해 사용자가 아직 보지 않은 영화를 보고 그 사용자에게 새로운 영화를 추천할 수 있게 하는 것이다.
- Our job in developing a recommender system is to come up with a learning algorithm that can automatically go fill in these missing values for us so that we can look at, say, the movies that the user has not yet watched, and recommend new movies to that user to watch.
Coursera 16-2 Content Based Recommendations (14:31)
우리가 하고 싶은 것은 이런 이용자들을 보면서 그들이 아직 rating 안한 다른 영화들을 어떻게 rating할지 예측하는 것이다. 이를 위한 첫번째 접근법은 Content based recommendation이라 한다.
- What we would like to do is look at these users and predict how they would have rated other movies that they have not yet rated.
- I’d like to talk about our first approach to building a recommender system. This approach is called content based recommendations.
예제_ Content-based recommendation

만약 우리가 위와 같은 feature들을 가지고 있다면, 각각의 영화는 feature vector로 표현될 수 있다.
- if we have features like these, then each movie can be represented with a feature vector.
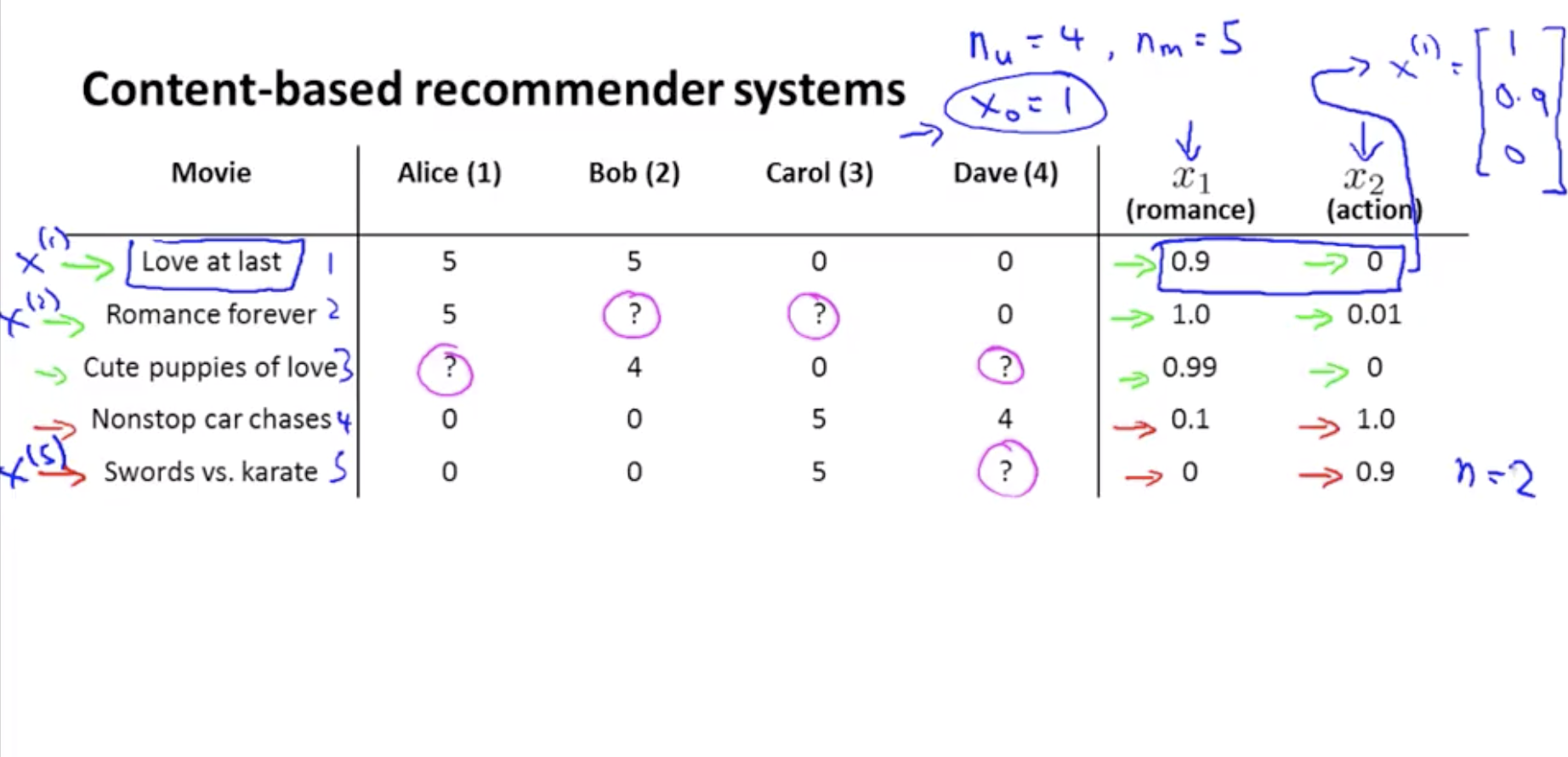
n : feature의 수. x(i) 에서 constant(x0) 제외한 개수.
x(1) = Love at last 에 대한 feature vector (1=x0(constant), 0.9=x1, 0=x2) \(x^{(1)}=~\left[ \begin{array}\ ~1 \\\\ 0.9\\\\ ~0 \end{array} \right]\)
예측을 하기 위해 각 사용자의 rating을 예측하는 것을 user 각각의 linear regression 문제로 생각할 수 있다.
- In order to make predictions here’s one thing that we do which is that we could treat predicting the ratings of each user as a separate linear regression problem.
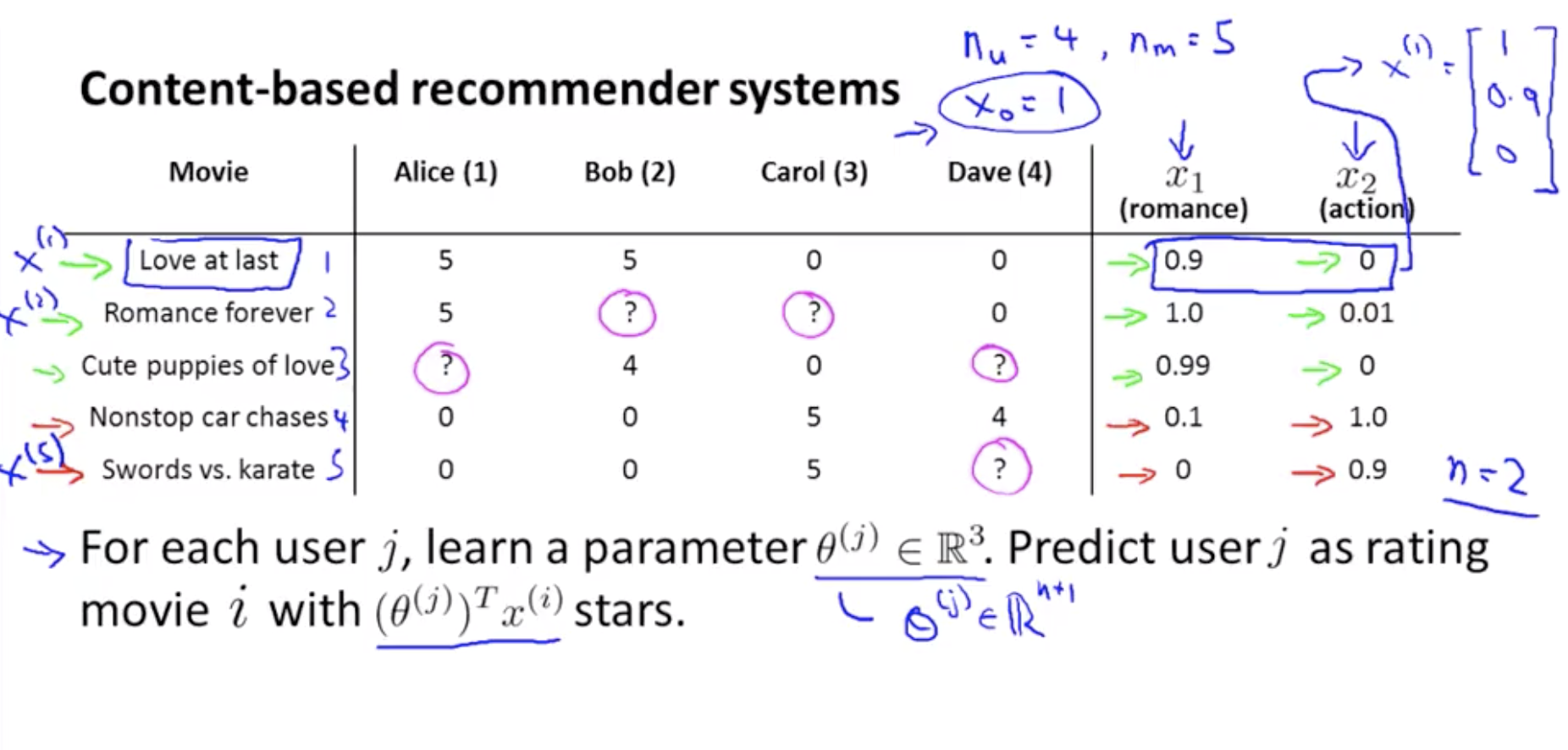 θ(j) : parameter vector
θ(j) : parameter vector
(θ(j))Tx(i) : predictied rating
예를 들어 Alice가 Cute puppie of love를 어떻게 생각하는지 보려면
(θ(1))Tx(3) = 01 + 50.99 + 00 = 4.95
이므로 Alice는 Cute puppies of love를 보고 4.95점을 낼 것이라는 결론을 낼 수 있다.
이렇듯 사람마다 각기 다른 linear regression을 갖게 될 것이다.
어떻게 θ(j) 를 추정하는 것인가?
단순한 linear regression문제인데, 변수 벡터인 θ(j) 를 선택해서 여기서 예측된 값이 관측값과 가능한 가깝도록 하는 것이다.
- This is basically a linear regression problem. So what we can do is just choose a parameter vector theta j so that the predicted values here are as close as possible to the values that we observed in our training sets and the values we observed in our data.

m(j) : user j 에 의해 rating 된 movie 수 = number of movies
위의 식은 한개의 θ(j) 에 대한 식, 아래 식은 모든 θ(j) 에 관한 식이다.
Summation(예측값 ( (θ(j))Tx(i) ) - 실제값 ( y(i,j) ))^2 : MSE + regularization term (feature가 너무 커지지 않도록) 을 minimize하는 것이 θ(j) 를 추정하는 Optimization objective이다. 여기서 m(j) 의 경우 constant라 minimize 하는 데에 영향을 미치지 못하므로 지워도 무방하다.
위의 식을 minimize하면 user j의 rating 대한 예측을 할 parameter vector θ(j) 에 대한 꽤 좋은 추정치를 얻을 수 있다.
- If you minimize this as a function of theta j you get a good solution, you get a pretty good estimate of a parameter vector theta j with which to make predictions for user j’s movie ratings.
다시 정리하면 아래와 같다.

user j의 parameter인 θ(j) 를 학습하기 위해 이 optimization objective의 θ(j) 를 최소화한다.
- In order to learn theta j which is the parameter for user j, we’re going to minimize over theta j of this optimization objectives.
실제로 최소화를 하기 위해서 gradient descent update를 얻는다면, 아래와 같은 방정식들을 얻을 수 있다. 이것은 Learning rate와 같다.
k=0 일 때 regularization term이 필요가 없다.
- In order to actually do the minimization, if you were to derive the gradient descent update, these are the equations that you would get. So you take theta j, k, and subtract from an alpha, which is the learning rate, times these terms over here on the right.

정리
이 알고리즘을 content based recommendations, content based approach 이라 하는데, 이는 우리가 다른 영화에 feature 들을 사용할 수 있다고 가정하기 때문이다. 그래서 이 feature들은 영화의 내용이 무엇인지, 이 영화가 얼마나 로맨틱한지, 이 영화에서 얼마나 많은 액션이 나오는지를 반영하는 것이었다. 그리고 실제로 features들을 사용해 예측했다. 하지만 모든 영화에서 이러한 feature들을 얻는건 쉬운일이 아니다. 그래서 다음 비디오에서는 content based recommendations이 아닌 새로운 접근법에 대해 이야기 할 것이다.
- This particular algorithm is called a content based recommendations, or a content based approach, because we assume that we have available to us features for the different movies. And so where features that capture what is the content of these movies, of how romantic is this movie, how much action is in this movie. And we’re really using features of a content of the movies to make our predictions. But for many movies, we don’t actually have such features. Or maybe very difficult to get such features for all of our movies, for all of whatever items we’re trying to sell. And so, in the next video, we’ll start to talk about an approach to recommender systems that isn’t content based and does not assume that we have someone else giving us all of these features for all of the movies in our data set.
