1. Tensorflow 활용하기
in Data on Deep Learning
파이썬을 이용한 머신러닝, 딥러닝 실전개발 입문
파이썬을 이용한 머신러닝, 딥러닝 실전개발 입문 책을 바탕으로 코드 리뷰 및 정리를 했습니다. 자세한 내용은 책과 강의를 참고해주세요.
link: github
5. 딥러닝
5-1. Tensorflow
- 대규모 숫자 계산을 할 수 있는 범용적인 라이브러리. 머신러닝과 딥러닝에 주로 사용하는 라이브러리다. 계산식을 모두 만들어 놓은 후, 데이터를 하나하나 넣으며 실행하는 구조입니다.
- 단순한 숫자 뿐만 아니라 영상과 음성처리도 가능합니다.
- 여담으로 Tensorflow의 Tensor는 다차원 행렬 계산을 의미한다. 따라서 Tensorflow는 다차원 행렬 연산을 흐르게 한다는 의미가 됩니다.
간단한 실습
Tensorflow에서 상수를 정의하고, 연산을 정의합니다. Tensorflow는 연산을 직접 하는것이 아니라 정의만 하는 것이고, 결과값은 상수가 아니라 데이터 플로 그래프라는 객체입니다. 이를 run() 메소드의 매개변수로 전달해야 계산이 시작됩니다.
import tensorflow as tf #상수 정의 a=tf.constant(1234) b=tf.constant(5000) #계산정의 add_op=a+b #세션 시작 sess=tf.Session() res=sess.run(add_op) print(res)
변수 표현 방법
import tensorflow as tf
#상수 정의
a=tf.constant(120,name="a")
b=tf.constant(130,name="b")
c=tf.constant(140,name="c")
#변수 정의
v=tf.Variable(0, name="v")
#데이터 플로우 그래프 정의
calc_op=a+b+c
assign_op=tf.assign(v,calc_op) #변수에 연산값 대입
#세션 실행
sess=tf.Session()
sess.run(assign_op)
#v내용 출력하기
print(sess.run(v))
플레이스 홀더
위의 예제들은 데이터 플로우 그래프를 먼저 만들고 그것을 실행하는 구조였습니다.
플레이스 홀더란 미리 값을 넣은 공간을 만들어 놓는 것으로 구축하면서 값을 넣는게 아니라 세션을 실행할 때 플레이스 홀더에 값을 넣고 실행하게 됩니다.
import tensorflow as tf
#플레이스 홀더 정의하기
a=tf.placeholder(tf.int32, [3]) #정수 자료형 3개를 가진 배열
#배열을 모든 값을 2배하는 연산 정의하기
b=tf.constant(2)
x2op=a*b
#세션 실행
sess=tf.Session()
#플레이스 홀더에 값을 넣고 실행
r1=sess.run(x2op, feed_dict={a:[1,2,3]})
print(r1)
r2=sess.run(x2op, feed_dict={a:[10,20,30]})
print(r2)
배열의 크기를 원하는데로 지정하고 싶다면 다음과 같이 placeholder 내의 배열을 None이라 지정해 주면 됩니다.
import tensorflow as tf
#플레이스 홀더 정의하기
a=tf.placeholder(tf.int32, [None]) #배열 크기 지정 x
#배열을 모든 값을 10배하는 연산 정의하기
b=tf.constant(10)
x10op=a*b
#세션 실행
sess=tf.Session()
#플레이스 홀더에 값을 넣고 실행
r1=sess.run(x10op, feed_dict={a:[1,2,3,4,5]})
print(r1)
r2=sess.run(x10op, feed_dict={a:[10,20]})
print(r2)
Tensorflow를 활용한 머신러닝
전단원 머신러닝 에서 활용한 bmi 데이터에 Tensorflow를 활용해 볼 것입니다.
Crossentropy : 2개의 확률 분포 사이에 정의되는 척도. 확률변수의 평균 정보량 이자 불확실성의 정도를 의미하며 값이 작을수록 정확한 값을 의미합니다.
p(x) 를 정답레이블, q(x) 를 예상레이블이라 할 때 Cross entropy의 식은 아래와 같습니다.
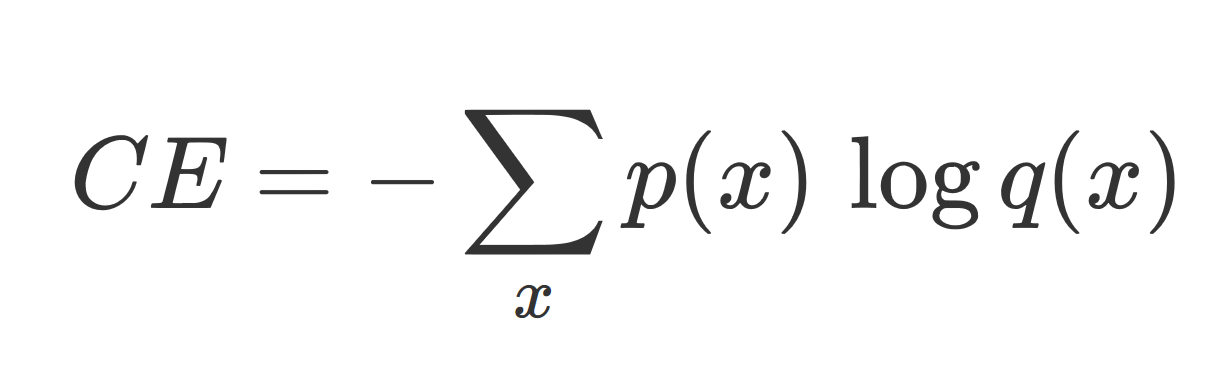
import pandas as pd import numpy as np import tensorflow as tf #csv 파일 로드 data=pd.read_csv("bmi.csv") #정규화 data["height"]=data["height"]/200 data["weight"]=data["weight"]/100 #레이블을 배열로 변환하기 #- thin=(1,0,0) / normar=(0,1,0) / fat=(0,0,1) bclass={"thin":[1,0,0],"normal":[0,1,0],"fat":[0,0,1]} data["label_pat"]=data["label"].apply(lambda x: np.array(bclass[x])) #테스트를 위한 데이터 분류 test_csv=data[15000:20000] test_pat=test_csv[["weight", "height"]] test_ans=list(test_csv["label_pat"]) #데이터플로우 그래프 구축하기 #플레이스홀더 선언하기 x=tf.placeholder(tf.float32, [None,2]) # 키와 몸무게 데이터 넣기 Y=tf.placeholder(tf.float32, [None,3]) # 정답 레이블 넣기 #변수 선언하기 W=tf.Variable(tf.zeros([2,3])) #가중치 b=tf.Variable(tf.zeros([3])) #bias #소프트맥스 함수정의 y=tf.nn.softmax(tf.matmul(x,W)+b) #행렬곱 #모델 훈련 cross_entropy=-tf.reduce_sum(Y*tf.log(y)) optimizer=tf.train.GradientDescentOptimizer(0.01) #0.01: 학습계수 train=optimizer.minimize(cross_entropy) #정답률 구하기 predict=tf.equal(tf.argmax(y,1), tf.argmax(Y,1)) accuracy=tf.reduce_mean(tf.cast(predict, tf.float32)) #세션 시작 sess=tf.Session() sess.run(tf.global_variables_initializer()) #변수 초기화 #학습시키기 for step in range(3500): i = (step*100)%14000 #14000과 나눴을 때의 나머지 rows=data[1+i:1+i+100] x_pat=rows[["weight","height"]] y_ans=list(rows["label_pat"]) fd={x:x_pat, Y:y_ans} sess.run(train, feed_dict=fd) if step%500==0: ce=sess.run(cross_entropy, feed_dict=fd) acc=sess.run(accuracy, feed_dict={x:test_pat, Y:test_ans}) print("step=", step, "cre=", ce, "acc=", acc) #최종적인 정답률 acc=sess.run(accuracy, feed_dict={x:test_pat, Y:test_ans}) print("정답률=",acc)step= 0 cre= 109.17177 acc= 0.3862 step= 500 cre= 52.821487 acc= 0.8258 step= 1000 cre= 43.839874 acc= 0.8684 step= 1500 cre= 41.017212 acc= 0.9468 step= 2000 cre= 37.52663 acc= 0.961 step= 2500 cre= 35.080284 acc= 0.9604 step= 3000 cre= 30.37377 acc= 0.9464 정답률= 0.9706
