4. 외국어 문장 판별
in Data on Machine Learning
파이썬을 이용한 머신러닝, 딥러닝 실전개발 입문
파이썬을 이용한 머신러닝, 딥러닝 실전개발 입문 책과 강의를 바탕으로한 코드 리뷰 및 정리입니다. 자세한 내용은 책과 강의를 참고해주세요.
link: github
4. 머신러닝
4-4. 외국어 문장 판별
판정 방법
언어가 다르면 알파벳의 출현 빈도가 다르다는 성질을 이용한다. Input vector로 각 알파벳의 출현 빈도의 비율을 이용한다.
샘플 데이터 수집
위키피디아에서 무작위로 기사를 추출하고 각 언어의 식별자에 맞게 저장한다. 간단하게 영어(en), 프랑스어(fr), 인도네시아어(id), 타갈로그어(tl)로 테스트데이터를 만들어 사용하였다.
언어 판별 프로그램
from sklearn import svm, metrics
import glob, os.path, re, json
def check_freq(fname):
basename=os.path.basename(fname)
lang=basename.split("-")[0]
#텍스트 추출하기
with open(fname, "r", encoding="utf-8") as f:
text=f.read()
text=text.lower() #소문자 변환
#알파벳 출현 빈도 구하기
code_a=ord("a")
code_z=ord("z")
cnt=[0 for n in range(0,26)] #26개의 0
#알파벳 출현 횟수 구하기
for char in text:
code_current=ord(char)
if code_a <= code_current <= code_z: #a와 z 사이에 있을 때
cnt[code_current-code_a]+=1
#정규화하기
total=sum(cnt)
freq=list(map(lambda n: n/total, cnt))
return (freq, lang)
#각 파일 처리하기
def load_files(path):
freqs=[]
labels=[]
file_list=glob.glob(path)
for fname in file_list:
r=check_freq(fname)
freqs.append(r[0])
labels.append(r[1])
return {"freqs":freqs, "labels":labels}
data=load_files("./language/train/*.txt")
test=load_files("./language/test/*.txt")
#JSON으로 결과 저장
with open ("./language/freq.json","w",encoding="utf-8") as fp:
json.dump([data, test],fp)
#학습하기
clf=svm.SVC()
clf.fit(data['freqs'], data['labels'])
#예측하기
result=clf.predict(test['freqs'])
#결과테스트하기
score=metrics.accuracy_score(test["labels"],predict)
report=metrics.classification_report(test["labels"],predict)
print("정답률=",score)
print("리포트=",report)
정답률= 0.875
리포트= precision recall f1-score support
en 0.67 1.00 0.80 2
fr 1.00 1.00 1.00 2
id 1.00 0.50 0.67 2
tl 1.00 1.00 1.00 2
avg / total 0.92 0.88 0.87 8
각 언어당 5개의 데이터로도 꽤 괜찮은 정답률이 나온다. 각 언어에 따라 알파벳 출현 빈도가 다르다는 것을 알 수 있다. 88%가 된 주범인 인도네시아어의 데이터를 확인해보니 영어가 굉장히 많이 섞여 있어 잘못 인식했던 것으로 파악했다. 또한 그 나라 특유의 알파벳 (é와 같이 악센트가 붙은 알파벳)을 제외하여 정확도에 아쉬움을 줬을 수도 있다고 생각한다.
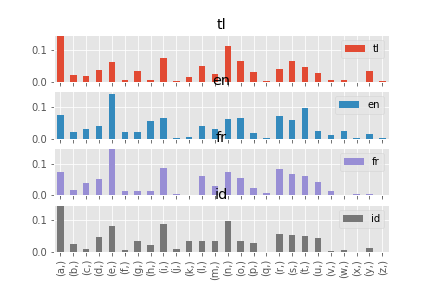
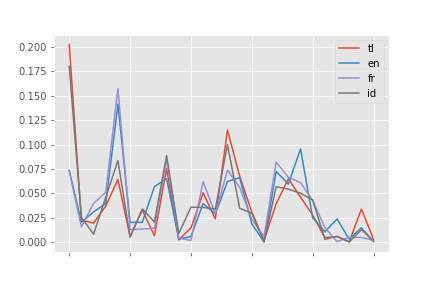
데이터분포를 그래프로 확인하기
#데이터 그래프 그리기
import matplotlib.pyplot as plt
import pandas as pd
import glob, os.path
files=glob.glob("./language/train/*.txt") #폴더 내 텍스트 파일 추출
train_data=[]
train_label=[]
for fname in files:
#레이블 구하기
basename=os.path.basename(fname)
lang=basename.split("-")[0]
#텍스트 추출하기
with open(fname, "r", encoding="utf-8") as f:
text=f.read()
text=text.lower() #소문자 변환
#알파벳 출현 빈도 구하기
code_a=ord("a")
code_z=ord("z")
cnt=[0 for n in range(0,26)] #26개의 0
for char in text:
code_current=ord(char)
if code_a <= code_current <= code_z:
cnt[code_current-code_a]+=1
#정규화하기
total=sum(cnt)
freq=list(map(lambda n: n/total, cnt))
#리스트에 넣기
train_label.append(lang)
train_data.append(freq)
#그래프 준비하기
graph_dict={}
for i in range(0,len(train_label)):
label=train_label[i]
data=train_data[i]
if not (label in graph_dict):
graph_dict[label]=data
asclist=[[chr(n) for n in range(97,97+26)]]
df=pd.DataFrame(graph_dict, index=asclist)
print(df)
#바그래프
plt.style.use('ggplot')
df.plot(kind='bar', subplots=True, ylim=(0,0.15))
plt.savefig('lang-plot.png')
#라인그래프
plt.style.use('ggplot')
df.plot(kind='line')
plt.show()
tl en fr id
a 0.202369 0.073806 0.072599 0.180053
b 0.022730 0.020368 0.015761 0.025664
c 0.019562 0.031099 0.039836 0.008246
d 0.037057 0.039641 0.051129 0.046101
e 0.064196 0.141261 0.157111 0.083582
f 0.005786 0.020368 0.013031 0.005113
g 0.033062 0.020368 0.013527 0.034121
h 0.006750 0.056943 0.014396 0.020827
i 0.075492 0.065046 0.085629 0.088696
j 0.002342 0.003285 0.004344 0.009058
k 0.014740 0.005913 0.001862 0.035923
l 0.050558 0.039641 0.062050 0.035680
m 0.023832 0.028909 0.029039 0.033975
n 0.114892 0.062199 0.073964 0.099912
o 0.067640 0.066141 0.056217 0.034819
p 0.030858 0.018835 0.023455 0.029722
q 0.001791 0.000438 0.005833 0.000179
r 0.039399 0.072492 0.082030 0.056879
s 0.065023 0.059571 0.066518 0.054380
t 0.046150 0.095488 0.061057 0.050208
u 0.027828 0.024967 0.042690 0.043260
v 0.004822 0.010731 0.015140 0.003003
w 0.005786 0.023872 0.000745 0.006233
x 0.000413 0.003066 0.005088 0.000308
y 0.033889 0.014893 0.004964 0.012921
z 0.003031 0.000657 0.001986 0.001136
웹 애플리케이션 만들기
애플리케이션을 실행시킬 때마다 새로 데이터를 학습시키는 일은 불필요한 일이다. 따라서 학습시킨 매개변수를 저장하고 활용을 하게끔 할 것이다.
from sklearn import svm
from sklearn.externals import joblib
import json
#각 언어의 출현 빈도 데이터 (JSON) 읽어 들이기
with open ("./language/freq.json","r",encoding="utf-8") as fp:
d=json.load(fp)
data=d[0]
#데이터 학습시키기
clf=svm.SVC()
clf.fit(data["freqs"], data["labels"])
#학습 데이터 저장하기
joblib.dump(clf, "./language/freq.pkl")
print("ok")
pkl은 주로 객체를 저장할 때 사용하는 확장자이다.
아래와 같은 폴더 구조를 만들어 보자.
<root>
|-<cgi-bin>
| |-webapp.py
| |-freq.pkl
root 폴더 안에 cgi-bin 폴더 안에 위의 코드를 통해 만든 freq.pkl 과 아래에서 만들 webapp.py 라는 파일이 들어가 있는 구조이다.
webapp.py 파일은 다음과 같다.
import cgi, os.path
from sklearn.externals import joblib
#학습 데이터 읽어들이기
pklfile=os.path.dirname(__file__)+"/freq.pkl"
clf=joblib.load(pklfile)
#텍스트 입력 양식 출력하기
def show_form(text, msg=""):
print("Content-Type : text/html ; charset=utf-8")
print("")
print("""
<html>
<body><form>
<textarea name="text" rows="8" cols="40">{0}</textarea>
<p><input type="submit" value="판정"></p>
<p>{1}</p>
</form></body></html>
""".format(cgi,escape(text), msg))
#판정하기
def detect_lang(text):
text=text.lower()
code_a, code_z = (ord("a"), ord("z"))
cnt=[0 for i in range(26)]
for char in text:
n=ord(char)-code_a
if 0<= n <= 26:
cnt[n]+=1
total=sum(cnt)
if total ==0: return "입력이 없습니다"
freq=list(map(lambda n: n/ total, cnt))
#언어 예측하기
res=clf.predict([freq])
#언어코드 한국어로 변환
lang_dic={"en":"영어", "fr":"프랑스어", "id":"인도네시아어", "tl": "타갈로그어"}
return lang_dic[res[0]]
#입력 양식의 값 읽어 들이기
form=cgi.FieldStorage()
text=form.getvalue("text", default="")
msg=""
if text!="":
lang=detect_lang(text)
msg="판정 결과: "+ lang
#입력 양식 출력
show_form(text, msg)
실행방법
$ cd cgi-bin경로 # ex)/Users/Desktop/root/cgi-bin) $ chmod +x webapp.py # 파이썬 권한 부여 $ cd .. $ python3 -m http.server --cgi 8080이후 웹 브라우저에서 아래의 URL로 접속하면 된다.
http://localhost:8080/cgi-bin/webapp.py학습량이 부족해 너무 짧은 문장은 잘못 구분하는 경우가 있지만, 2문장 이상인 경우는 꽤 잘 구분했다.


시간을 내어 크롤링을 바탕으로 학습을 꽤 시켜볼 예정이다.
