5. 로그인이 필요한 사이트에서의 크롤링
파이썬을 이용한 머신러닝, 딥러닝 실전개발 입문
파이썬을 이용한 머신러닝, 딥러닝 실전개발 입문 책과 강의를 바탕으로한 코드 리뷰 및 정리입니다. 자세한 내용은 책과 강의를 참고해주세요.
link: github
2. 고급 스크레이핑
2-1. 로그인이 필요한 사이트에서 다운받기
HTTP 통신
HTTP 통신은 기본적으로 브라우저에서 서버로의 요청(request)과 서버에서 브라우저로의 응답(response)로 이루어진다
기본적으로 무상태(stateless)통신.
무상태 통신이란 같은 URL에 여러번 접근해도 같은 데이터를 돌려주는 통신 = 이전에 어떤 데이터를 가져가는지에 대한 정보를 저장하지 않음
쿠키
HTTP통신으로는 회원제 사이트를 만들수 없기 때문에 ‘쿠키’가 생김
- 사이트에 방문하는 사람의 컴퓨터에 일시적으로 데이터를 저장 (4096Byte 까지만)
- 하지만 HTTP헤더를 기반으로 이뤄지므로 방문자가 데이터를 원하는 대로 변경할 수 있기 때문에 비밀 정보를 저장하기에는 알맞지 않음
세션
- 쿠키를 이용하나, 쿠키에는 방문자 고유 ID만 저장하고 실제 모든 데이터는 웹 서버에 저장.
- ID를 키값으로 확인하여 계속 통신을 진행 하는 상태유지 (stateful)통신을 구현.
requests 사용하기
기본적인 형태는 다음과 같다
import requests url="http://google.com" data={ "a"="10", "b"="20" } #세션 만들기 session=requests.session() response=session.get(url, data=data) #get,post,put 등 페이지의 요청을 모방한다 #로그인 실행 response.raise_for_status() print(responce.text)- ex) 한빛출판 네트워크 사이트에서 로그인 - 마이페이지 - 마일리지와 코인을 확인하는 예제
로그인 과정 분석하기
크롬의 개발자도구 - [Network]탭을 누르면 다음과 같은 창을 볼 수 있다
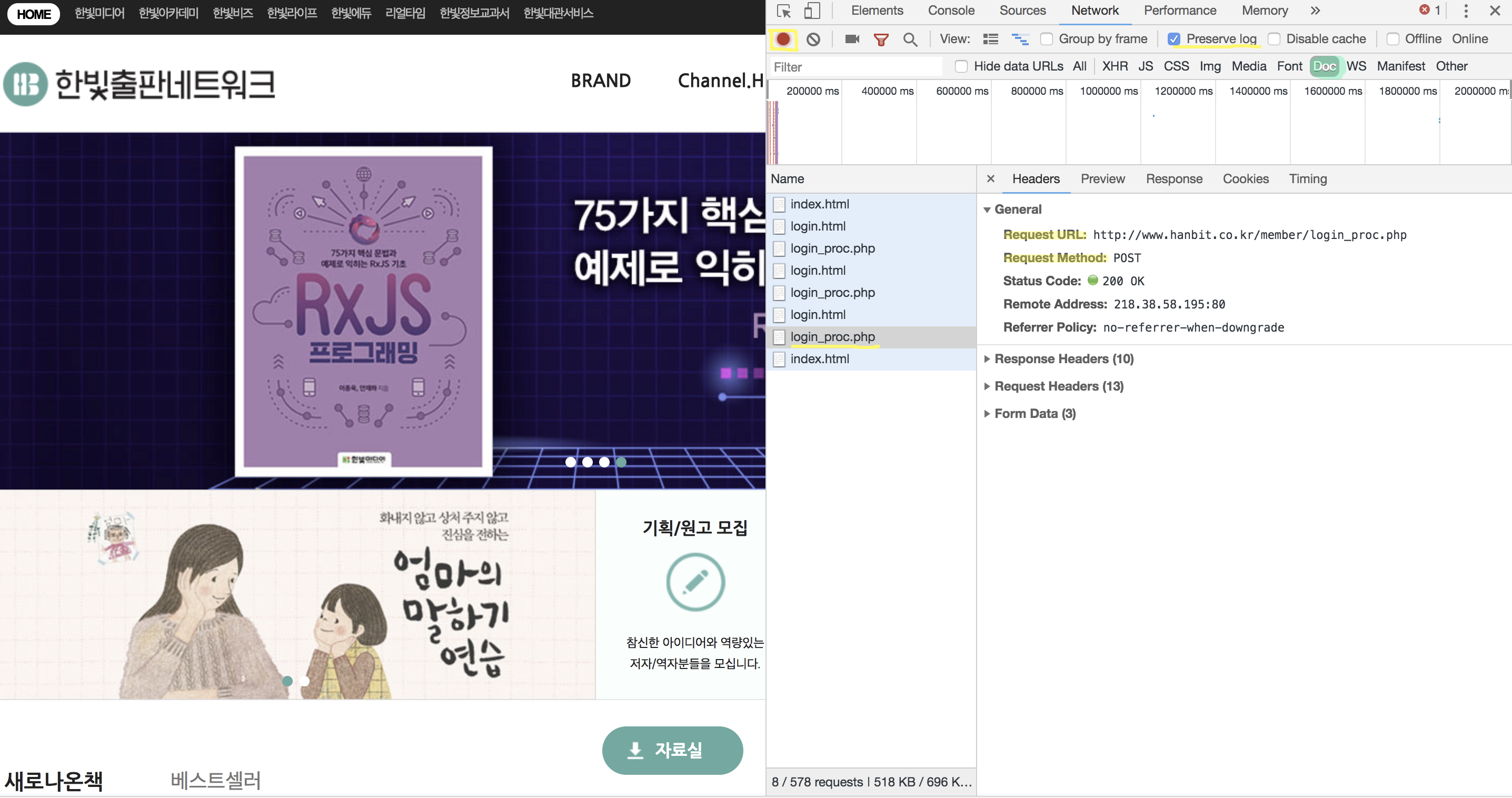
1) 우상단 왼쪽의 빨간불이 들어와 있는지 확인한다. (네트워크 상태 녹화 표시)
2)
Preserve log의 체크박스를 체크 한다. (로그 유지)3) DOC 설정
이 과정에서 로그인을 하면 ‘index.html -> login_pro.php -> login.html‘의 과정이 되는 것을 알 수 있고
*login_pro.php*의 과정에서 직접적인 로그인이 이루어 진 것을 알 수 있다.General부분의 Request URL이 로그인 페이지의 url이 되고, Request Method가 페이지의 요청방식이 된다.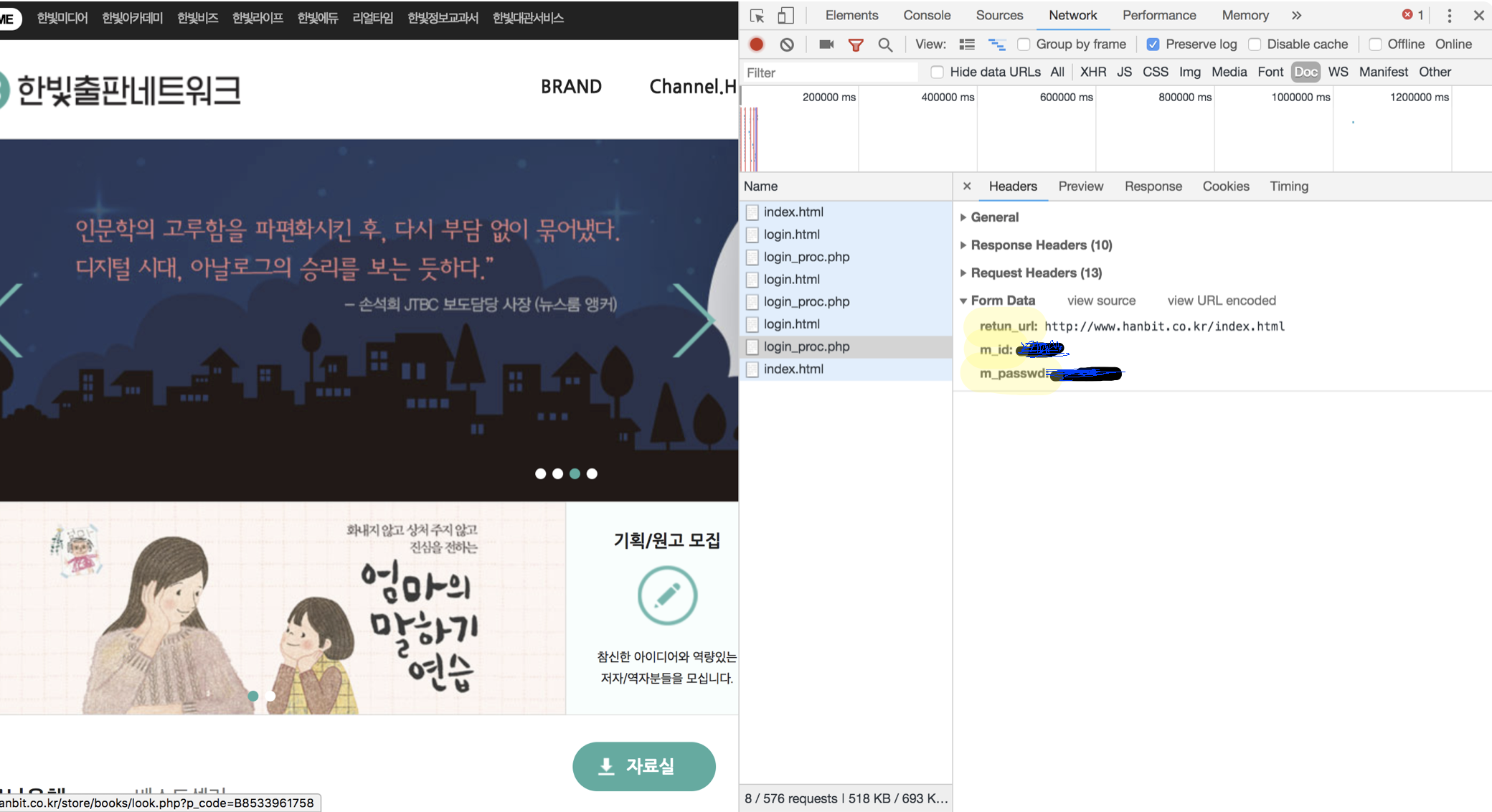
Form Data에 보이는 return_url, m_id, m_passwd가 로그인할 때 가져와야 하는 데이터가 된다.import requests from bs4 import BeautifulSoup #세션만들기 session=requests.session() #로그인 하는 페이지의 general-requestURL에서 url 가져옴 url="http://www.hanbit.co.kr/member/login_proc.php" #가져오고 싶은 데이터 (form data) data={ "return_url":"http://www.hanbit.co.kr/index.html", "m_id":"아이디", "m_passwd":"비밀번호" } response=session.post(url, data=data ) #요청을 모방하면됨 (get, post, put 등) #로그인 실행 response.raise_for_status() #마이페이지 접근 url="http://www.hanbit.co.kr/myhanbit/myhanbit.html" response=session.get(url) response.raise_for_status() #print(response.text) #HTML분석 (이코인 가져오기) soup=BeautifulSoup(response.text,"html.parser") #container > div > div.sm_mymileage > dl.mileage_section2 > dd text=soup.select_one(".mileage_section2 span").get_text() print("이코인:",text)requests.session()을 이용하면 쿠키를 사용하는 회원제 사이트에 로그인 해 다양하게 활용할 수 있다.
- ex) 한빛출판 네트워크 사이트에서 로그인 - 마이페이지 - 마일리지와 코인을 확인하는 예제
requests 모듈의 메소드
import requests #get요청 r=requests.get("http://google.com") #post요청 formdata={ "key1":"value1", "key2":"value2" } r=requests.post("http://example.com", data=formdata) #그 밖의 요청 r=requests.put("http://httpbin.org/put") r=requests.delete("http://httpbin.org/delete") r=requests.head("http://httpbin.org/get")return 값에 있는 text, context 속성을 참조하면 내부 데이터를 확인할 수 있다.
ex) 현재 시간에 대한 데이터 추출, 추출한 데이터를 텍스트 형식과 바이너리 형식으로 출력
#데이터 가져오기 import requests r=requests.get("http://api.aoikujira.com/time/get.php") #텍스트 형식으로 데이터 추출하기 text=r.text print(text) #바이너리 형식으로 데이터 추출하기 bin=r.content print(bin)ex) 바이너리를 활용한 이미지 저장. (이미지 - 바이너리 데이터)
#이미지 데이터 추출하기 import requests r=requests.get("http://wikibook.co.kr/wikibook.png") #바이너리 형식으로 데이터 저장하기 with open ("test.png","wb") as f: f.write(r.content)
