4. 재귀적 호출을 이용한 크롤링
파이썬을 이용한 머신러닝, 딥러닝 실전개발 입문
파이썬을 이용한 머신러닝, 딥러닝 실전개발 입문 책과 강의를 바탕으로한 코드 리뷰 및 정리입니다. 자세한 내용은 책과 강의를 참고해주세요.
link : github
1. 크롤링과 스크레이핑
1-4. 링크에 있는 것을 한꺼번에 내려받기
- 링크 대상이
HTML인 경우 : 추가적인 처리 + 재귀적 다운
1) 상대 경로를 전개하는 방법
urllib.parse.urljoin() - urljoin(base,path) : base를 기반으로 Path를 절대경로로 만들어 준다.
from urllib.parse import urljoin base="http://example.com/html/a.html" print(urljoin(base, "b.html")) print(urljoin(base, "sub/c.html")) print(urljoin(base, "../index.html")) print(urljoin(base, "../img/hoge.png")) print(urljoin(base, "../css/hoge.css"))
2) 재귀적으로 HTML페이지를 처리하는 방법
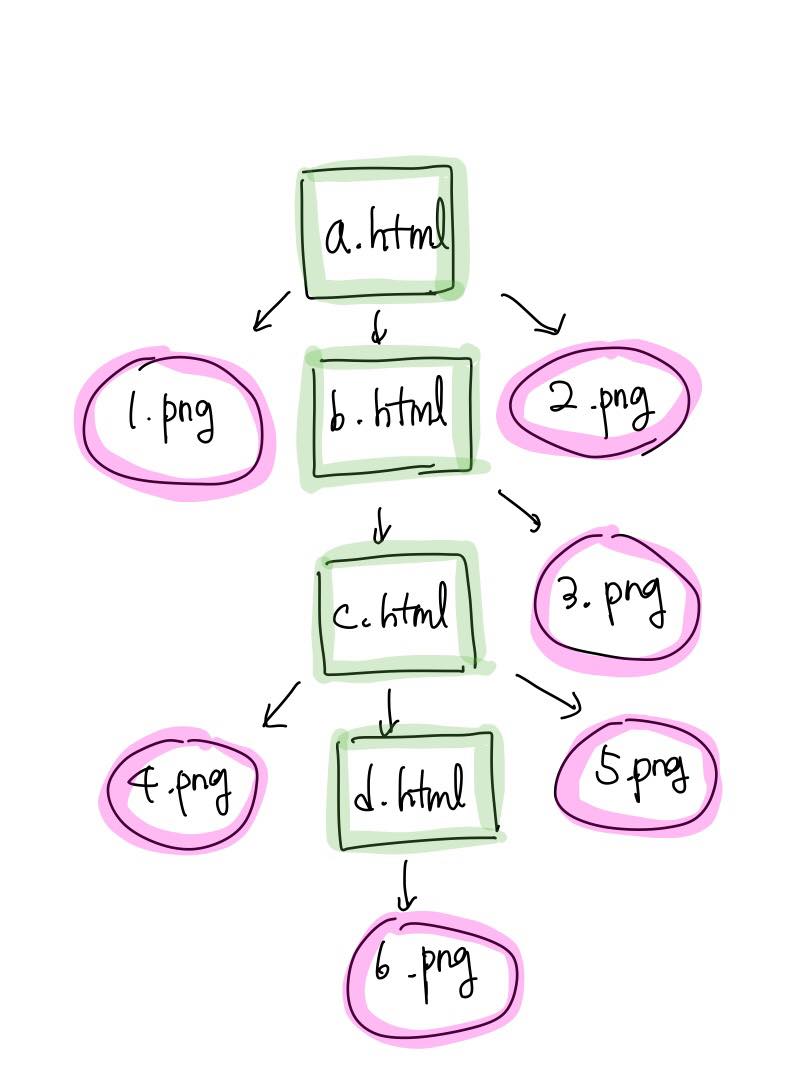
링크로 계속 이어져 있기 때문에 재귀적으로 처리해야 연결된 모든 HTML 페이지를 다운받을 수 있다.
시스템에서 직접 폴더를 만드는 코드가 포함되어있어서 잘 이해가 안되는 코드가 있을 수 있다.
#파이썬 메뉴얼을 재귀적으로 다운받는 프로그램 #모듈읽기 from bs4 import BeautifulSoup from urllib.request import * from urllib.parse import * from os import makedirs import os.path, time, re #url="https://docs.python.org/3.5/library/" #a #이미 처리한 파일인자 확인하기 위한 변수 proc_files={} #HTML 내부에 있는 링크를 추출하는 함수 def enum_links(html,base): soup=BeautifulSoup(html, 'html.parser') links=soup.select("link[rel='stylesheet']") #CSS #어디에있는 링크지 links+=soup.select("a[href]") #링크 result=[] #href 속성을 추출하고 링크를 절대경로로 변환 (속에 있는 링크들이 상대경로로 되어있기 때문) for a in links: href=a.attrs['href'] url=urljoin(base,href) result.append(url) return result #페이지 안에 있는 경로들 다 절대경로로 들어가 있음 #파일을 다운받고 저장하는 함수 def download_file(url): o=urlparse(url) #? savepath="./"+o.netloc+o.path #? if re.search(r"/$",savepath): #폴더라면 index.html savepath += "index.html" #? savedir=os.path.dirname(savepath) #모두 다운됐는지 확인 if os.path.exists(savepath): return savepath #다운받을 폴더 생성 if not os.path.exists(savedir): print("mkdir=",savedir) makedirs(savedir) #파일다운받기 try: print("download=",url) urlretrieve(url,savepath) #savepath 이름으로 다운 time.sleep(1) return savepath except: print("다운실패",url) return None #HTML을 분석하고 다운받는 함수 def analyze_html(url,root_url): savepath=download_file(url) if savepath is None: return #continue? if savepath in proc_files : return proc_files[savepath]=True #새로운 경로 proc_file에 넣어줌 print("analyze_html=",url) #링크 추출 html=open(savepath,"r",encoding='utf-8').read() #'r'? links=enum_links(html,url) for link_url in links: #링크가 루트 이외의 경로를 나타낸다면 무시 if link_url.find(root_url)!=0:#? if not re.search(r".css$",link_url): #? continue #HTML이라면 if re.search(r".(html|htm)$",link_url): #? #재귀적으로 HTML파일 분석하기 analyze_html(link_url, root_url) continue #기타 파일 download_file(link_url) if __name__=="__main__": # 다른데서도 위의 함수들 사용 가능 #URL에 있는 모든 것 다운받기 url="https://docs.python.org/3.5/library/" analyze_html(url,url)
